实验的“功效”究竟是什么意思?
在进行实验时,您通常关注的是测量某种效应:药物处理组的蛋白质浓度是否与对照组不同;敲除菌株的中位生存时间是否比野生型更长;不同处理组之间的基因表达是否存在差异?
您的实验利用来自不同总体(population)的样本收集数据并进行统计分析。其核心思想是:如果所寻找的效果确实存在于总体中,那么(希望)您能在样本中观察到它。然而,总体内部存在变异性,您无法始终确信从更广泛的总体中选取的样本能让您检测到目标效应。
简而言之,采用经典假设检验方法的分析通常以“无效应”为零假设,以“存在效应”为备择假设。在上述情境中,我们假设该效应确实存在于总体中。但仅因随机因素,您所选取样本生成的数据未能反映该效应。 换言之,您的数据可能得出大于0.05(或您设定的任何α值)的P值。正因如此,即使目标效应确实存在于您抽样的总体中,您也不会拒绝零假设(即不存在效应)!
检验的“功效”是指当零假设为假时,您拒绝零假设的概率。换言之,功效就是当您所寻找的效果确实存在于总体中时,您拒绝零假设的概率。 让我们重新审视本示例:我们最初指出效应确实存在于总体中,但由于总体内的变异性以及从总体中随机抽样,我们可能观察到该效应,也可能无法观察到。功效告诉我们观察到该效应的概率,它取决于许多因素,包括总体中的效应量、从总体中抽取的样本量,以及总体内的变异性。
从“无限次实验”的角度理解功效
假设我们使用t检验比较两个总体均值,且这两个总体的均值确实存在特定程度的差异。我们首先从两个目标总体中抽取样本,计算样本均值,进行t检验,并得到一个P值。由于所抽取总体的变异性,这个P值可能大于显著性水平α(通常为0.05),也可能小于α。
但现在假设我们从这两个总体中抽取新的样本并再次进行检验。由于总体变异性和抽样过程,样本值会略有不同,t检验也会得出不同的结果。这次新的检验将得到一个不同的P值,该值(同样)可能大于或小于显著性水平α。
现在假设我们不断重复这一过程。部分计算出的P值会小于α,此时我们会拒绝零假设;而另一些计算出的P值则会大于α,此时我们不会拒绝零假设。 我们最初的假设是总体均值存在差异,因此如果进行相同的实验(从同一总体中抽取相同样本量),那么在一定比例的实验中,P值会小于我们的阈值。如果实验重复进行无限次,那么P值小于阈值的实验所占的比例就是该实验的功效。
请注意,由于以下几个原因,这在现实生活中无法实现:
1.我们没有足够的时间或资源来进行无限次实验
2.更重要的是,我们无法确定所抽样的总体中是否确实存在该效应。如果我们早已知道存在某种效应,那么进行这些实验也就没什么意义了!
关于功效(及β值)的更严谨定义
通常,当您从总体中抽取样本时,您的目标是从中确定某个统计量(如均值、标准偏差等)。另一种统计量可能是两个样本均值之间的差值。还有一种统计量可能是样本均值之差除以两个样本的合并标准偏差。最后这种统计量实际上就是t检验中使用的t统计量。
无论您计算的是哪种统计量,由于样本是从更大的总体中抽取的,且该总体具有变异性,因此该统计量会有一个可能的取值范围。 如果您抽取许多不同的样本,几乎肯定会得到许多不同的统计量值。该统计量可能取值的分布由所谓的“抽样分布”给出。在观察统计量以确定不同总体之间是否存在预期的效应时,该统计量的可能值分布在很大程度上也依赖于该效应是否真实存在。
幸运的是,只要掌握足够的总体信息和预测效应信息,我们就可以分别在假设该效应存在和不存在的两种情况下,构建统计量的抽样分布。让我们以 t 统计量为例:
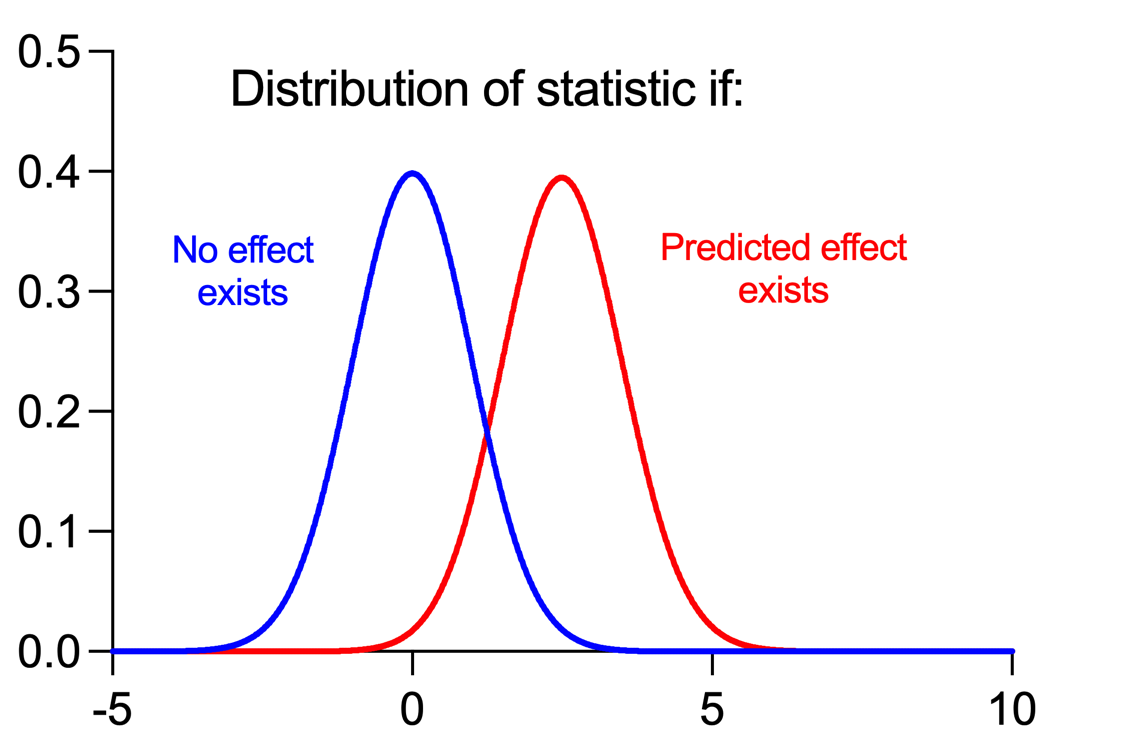
蓝色曲线是假设不存在效应时的抽样分布。请注意,该分布以零为中心,这在没有效应的情况下是合理的。然而,由于总体存在变异性,且样本是从总体中抽取的,因此即使不存在效应,仍有可能得到大于或小于零的t统计量。
红色曲线是假设存在特异性预测效应时的抽样分布。在此情况下,该分布的中心点约为2.5。这是因为如果预测效应确实存在,测得的t统计量远离零点的概率会大得多(但并非不可能为零)。
当您通过从这些总体中抽样并计算 t 统计量来进行实验时,您会将该 t 统计量与“临界值”进行比较,以确定所获得的结果是否统计学显著。这些曲线可以直观地展示这一过程。以下是零假设(蓝色曲线,无效应存在)的抽样分布及其临界 t 值(垂直线):
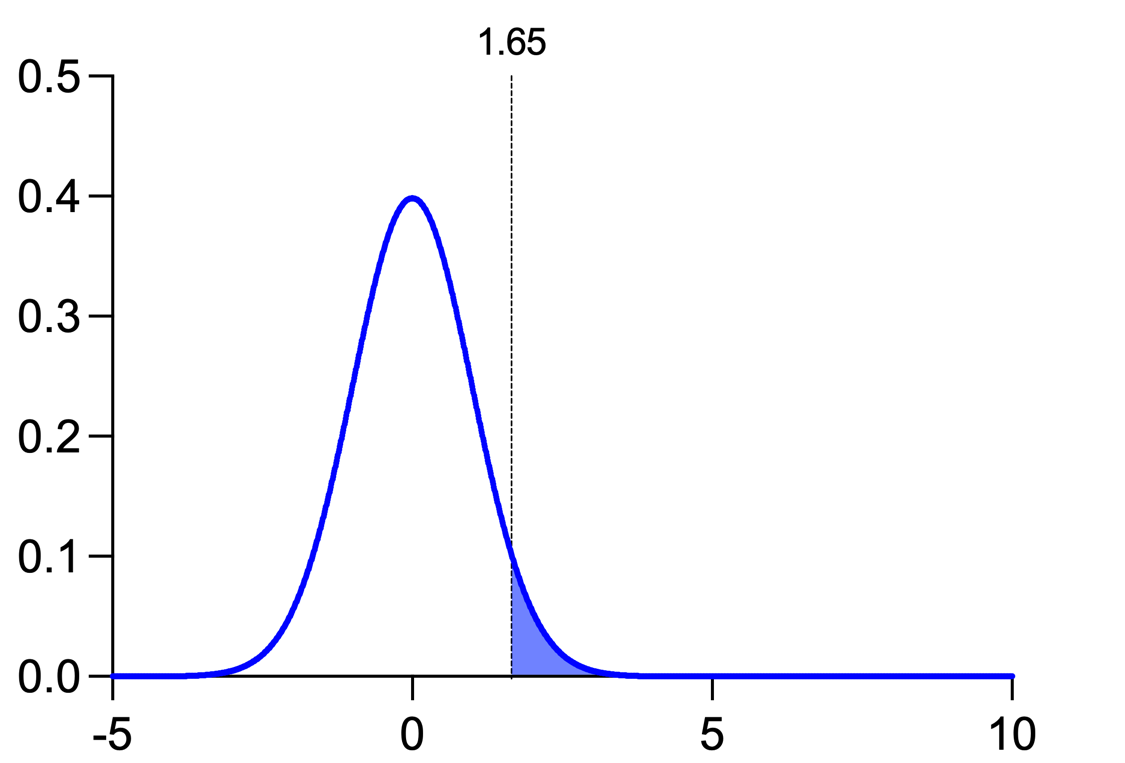
阴影区域代表在零假设成立的情况下,得到大于临界值的 t 统计量值的概率。在此情况下,阴影区域占该曲线下总面积的 5%。这体现了 α 的概念,即当零假设实际上成立时,拒绝零假设的概率。 若采用不同的α值,将得到不同的临界值,最终阴影区域所占的曲线长度也会随之改变。
同样地,临界值也可与红色曲线结合使用:
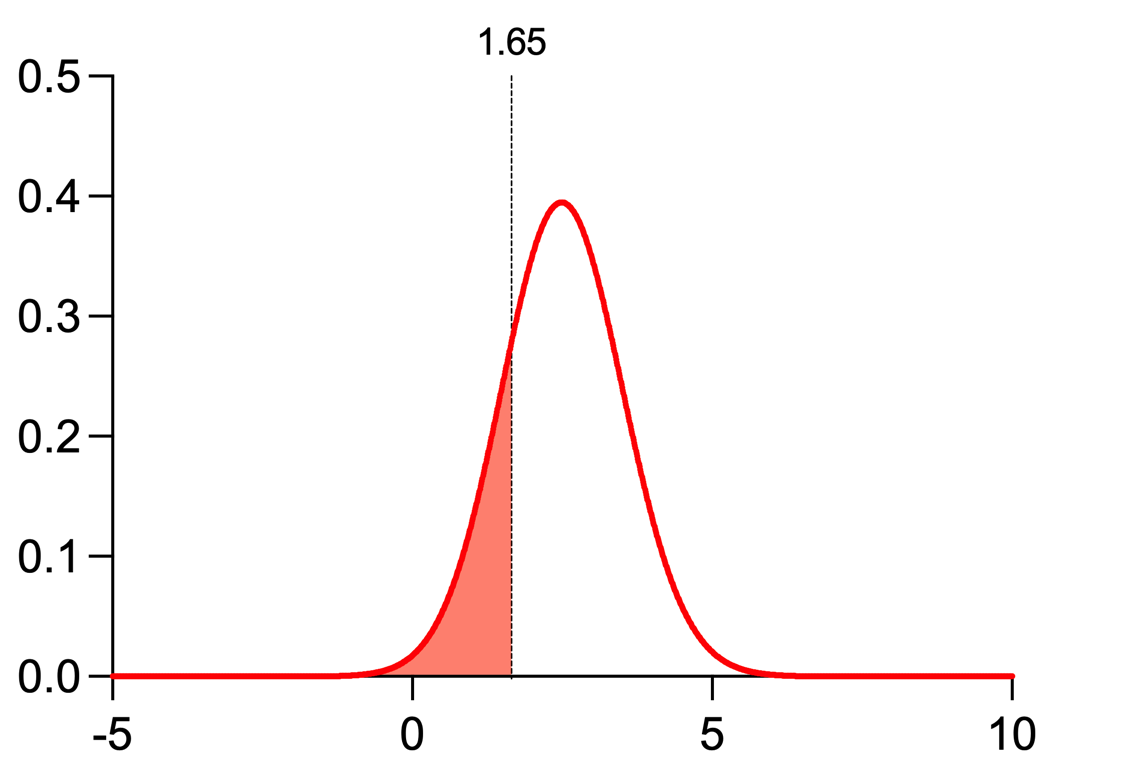
在此情况下,阴影区域代表当备择假设成立时,t统计量值小于临界值的概率。 此处的阴影区域占该曲线下总面积的20%。这体现了β的概念,即当零假设为假时未能拒绝零假设的概率(第二类错误)。换言之,即实际存在效应时未能检测到该效应的概率。 您可能会注意到,α(犯Ⅰ类错误的概率)是β(犯Ⅱ类错误的概率)的1/4,这些数值相当常见。一种理解方式是:采用这些数值意味着,避免犯Ⅰ类错误(假阳性)的重要性是避免犯Ⅱ类错误(假阴性)的4倍。
功效实际上直接由β推导而来:
功效 = 1 - β
因此,在上述β=0.20的示例中,功效即为0.8或80%。与α=0.05的情况类似,这只是功效常用的数值,但并非严格要求。最终,在设计实验时,应由您作为研究者决定希望达到的功效值。下一节将对此进行更详细的讨论。
综合上述图片和信息,我们可以得出以下结论:
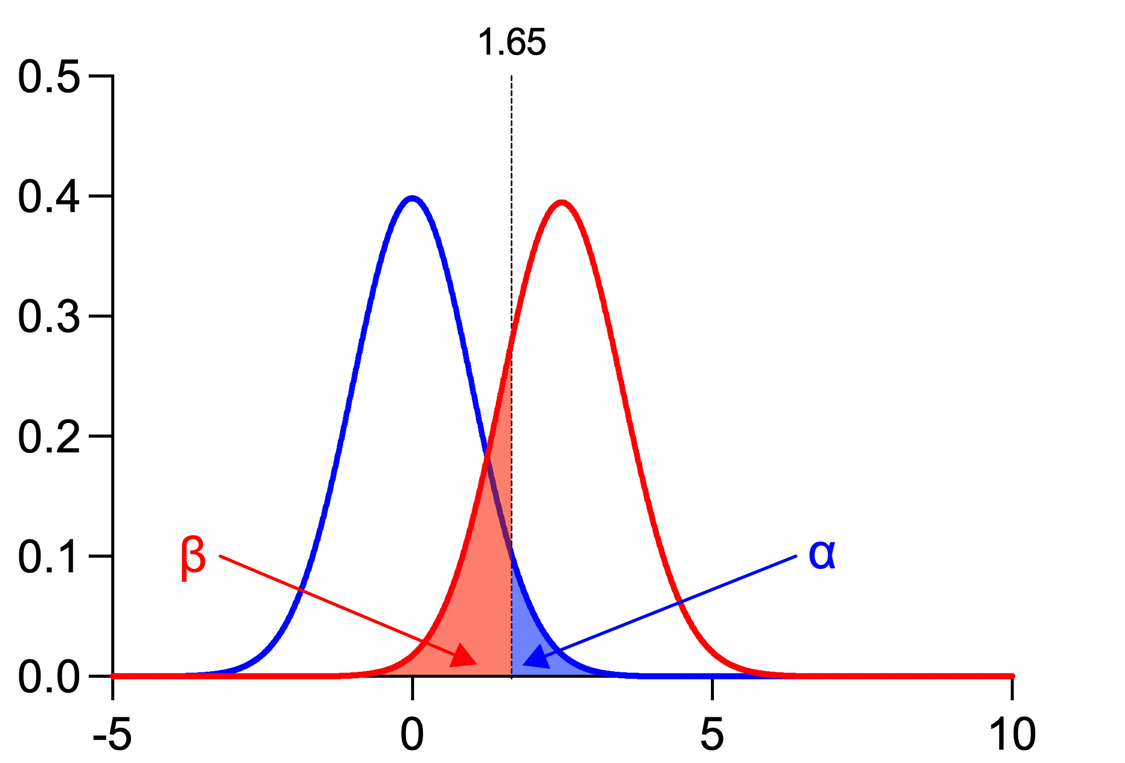
•α(α):Ⅰ类错误的概率(在零假设为真时将其拒绝,即“假阳性”),通常为0.05或5%
•Beta (β):II类错误的概率(在零假设为假时未拒绝零假设,即“假阴性”),通常为0.2或20%
•功效 (1-β):当零假设为假(即效应确实存在)时,拒绝零假设的概率,通常为 0.8 或 80%
我需要多大的功效?
功效是指在假设所研究的效应确实存在于抽样总体中时,实验从样本中得出“统计学显著”结果的概率。您需要多大的功效?以下指南或许有所帮助:
•如果某项实验的功效低于50%,那么只有当目标效应在半数实验中存在时,您才能检测到它。功效如此之低的研究实际上帮助不大,而且(可能更糟的是)很难被重复验证
•许多研究者会选择样本量以获得80%的功效。虽然这个标准是任意的,但被广泛采用
•理想情况下,可接受的功效应依赖于发生Ⅱ类错误的后果。
使用 Prism 进行功效分析
通过 Prism Cloud,可以针对各种实验设计进行功效分析(及样本量计算)。