在执行Cox比例风险回归时,Prism会提供两个值,用于表示每个预测变量对风险率的影响:
•参数估计量(下文将讨论)
•风险比(另见相关页面)
这两个数值是彼此的简单变换,因此传达的信息是相同的。如果您刚接触 Cox 回归,理解风险比可能更容易一些。
关于这些参数估计量和风险比所计算的 P 值的信息,可在专门的页面上查阅。
参数估计值
在Cox比例风险回归中,参数估计量的解读比Prism提供的其他形式的多重回归要稍显复杂。这是因为Cox比例风险回归所采用的模型旨在探究预测变量与风险率之间的关系。供参考,以下是该模型的一般形式:
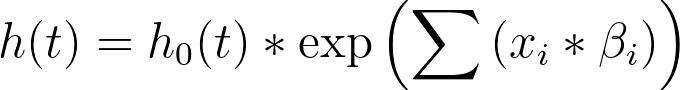
另一种呈现该模型的方式是将两边同时除以基线风险(h0(t))并取自然对数,结果为:
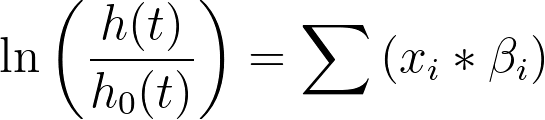
此即理解参数估计值的模型形式。例如,假设某项分析中唯一的预测变量是连续变量“年龄”。若“年龄”的参数估计值为 0.5,则模型将呈现如下形式:
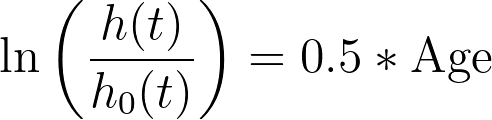
根据该模型,可以看出,如果“年龄”的值增加1,对数(对数风险率)的值将增加0.5。 尽管这些参数估计值呈现的是对数值的影响(从绝对值角度理解可能较为困难),但它们确实具有一个显著优势:参数估计值为正时,表明该预测变量的增加会导致危险率上升;而参数估计值为负时,则表明该预测变量的增加会导致危险率下降。
请记住,危险率的增加意味着发生目标事件的风险增加,而危险率的降低则意味着发生目标事件的风险降低。
标准误差与置信区间
参数估计值 - 顾名思义 - 仅仅是针对整个总体中某个未知值的估计值。了解参数实际值的唯一方法是收集整个总体的数据。例如,如果您想知道人类的平均身高,您可以(假设)测量每一个人的身高。然而,由于实际上无法做到这一点,您只能收集样本数据。 基于该样本,您会计算出一个平均值,而这个平均值会因所选样本中的随机变异性而存在一定误差。在Cox比例风险回归中,Prism会报告两个值,用于反映参数系数估计值中的误差程度:标准误差和剖面似然置信区间。
系数的标准误差可能难以解读,但简单来说,它反映了参数估计值的精确程度。
另一种理解“精确度”概念的方法是使用置信区间。这些数值能反映出您对所给参数估计值的置信程度。置信区间的普遍原理是:若重复进行同一实验无数次,并为每次重复实验构建置信区间,那么其中 95% 的区间(对于 95% 置信区间)将包含整个总体中的真实参数系数。 请注意,某些软件报告的是对称置信区间,这些区间是直接利用上述标准误差计算得出的。而Prism实际上计算的是更精确的剖面似然置信区间。这些区间在估计参数值周围可能是(且通常是)不对称的。