本示例摘自一部优秀的在线统计学教材《如何避免和发现统计学不当行为》。该研究评估了两种病媒控制方法与不采取控制措施相比,对牛的红细胞压积(PCV)的影响。三群奶牛被随机分配到三种处理组中。从每群奶牛中抽取四头牛的血液样本,并记录其红细胞压积值。
我们关注的因素是处理组。嵌套因素是牛群。由于每头牛仅接受一种处理,因此牛群因素嵌套在处理组因素之下。
1. 数据录入
创建一个嵌套表,并设置子列数量以匹配实际重复次数。在本示例中,每个处理组包含三个牛群,因此应创建包含三个子列的表。
输入数据时,将各重复组奶牛的数据堆叠在一起。
要为子列添加适当标签(如下文的“Herd1”),请双击子列标题以调出对话框,在其中输入子列标题。

注:
•请注意,重复组数据是堆叠排列的。这与 Prism 的常规操作方式不同。我们采用这种设置有两个原因。首先,它允许您为子列命名(如上文的“牛群 1”、“牛群 2”)。其次,这符合大多数文献中进行此类分析的方式。如果技术重复组数据是并列排列的,且不同行对应不同大鼠,Prism 的嵌套 t 检验分析将产生无意义的结果。
•每个子列中值的顺序是任意的。您可以随意打乱每个子列中的数据,结果不会改变。第 2 行中的值之间没有任何对应关系。
•各子列的顺序无关紧要。即使将“群组 2”和“群组 3”的数据互换,结果也完全相同。例如,控制数据的第二子列与处理组的第二子列之间没有任何关联。
•在本示例中,每个子列的数值个数相同(均为4)。嵌套单因素方差分析并不要求这一点,即使样本量不等也能正常运行。
•我们使用“嵌套单因素方差分析”这一名称,因为它最能准确描述该检验的用途。大多数书籍将其称为嵌套双因素方差分析,因为其中一个因素(本示例中为牛群)嵌套在另一个因素(处理)之中。
•Prism无法对超大规模数据集运行嵌套方差分析,并会显示相应提示信息。何谓“超大规模”?详情请参阅此处
2. 运行分析
点击“分析”,然后从“分组分析”列表中选择“嵌套单因素方差分析”。
在第一个选项卡中,选择是否为每个数据集生成总体均值及 95% 置信区间的图表,以及是否在表格结果中显示拟合优度。
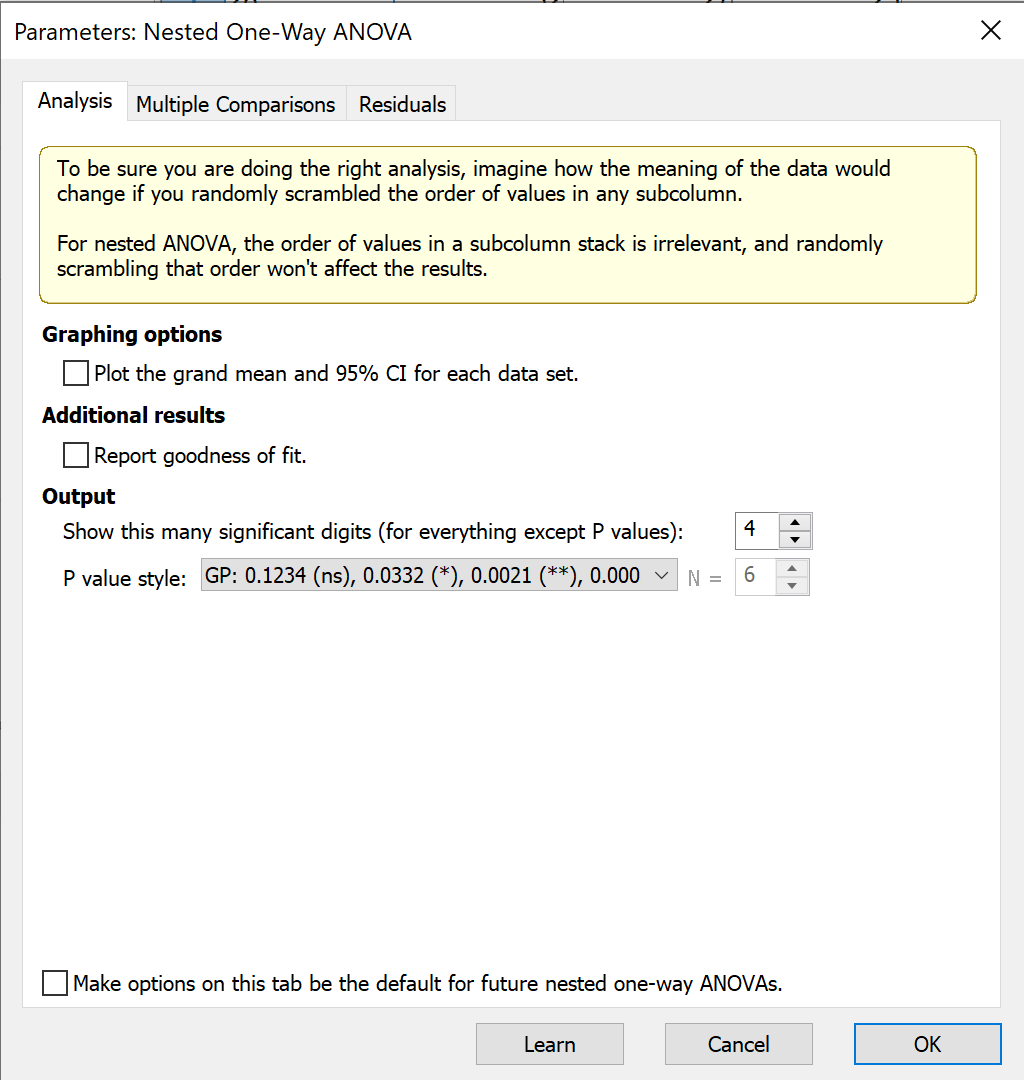
第二个选项卡提供多重比较选项,第三个选项卡则提供多种绘制残差图的选项。