在数据堆栈中识别异常值非常简单。在列数据表中单击“分析”,然后从列数据分析列表中选择“识别异常值”。Prism 只需数据集中包含三个值即可执行异常值检验。
注意:本页面说明了如何从设置为“列数据”的数据表中的一组值中识别异常值。Prism 还可以在非线性回归过程中识别异常值。
使用哪种方法?
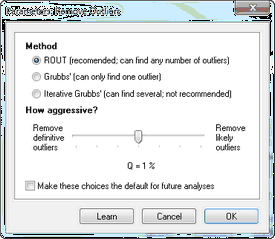
Prism 提供了三种识别异常值的方法:
ROUT 法
我们开发了 ROUT 方法,用于在通过非线性回归拟合曲线时检测异常值。Prism 将该方法应用于检测列数据表中一组值中的异常值。ROUT 方法可识别一个或多个异常值。
Grubbs 法
Grubbs 检验可能是识别异常值最常用的方法。该方法也被称为 ESD 方法(极值斯蒂尔德偏差)。它只能在每个数据集中识别一个异常值。Prism 使用双侧 Grubbs 检验,这意味着它将检测出远大于其余值的数值,或远小于其余值的数值。
迭代格鲁布斯法
尽管格鲁布斯法最初设计用于检测单个异常值,但常被扩展以检测多个异常值。实现方法很简单:若发现一个异常值,则将其移除,并对剩余值再次进行格鲁布斯检验。若第二次检验发现异常值,则移除该值,并进行第三次检验……
虽然格鲁布斯检验在数据集中检测单个异常值方面表现良好,但在处理多个异常值时效果不佳。在小型数据集中,第二个异常值的存在可能会导致第一个异常值无法被检测到。这种现象被称为掩蔽效应。格鲁布斯法通过计算某个值与均值的差值,再将该差值除以所有值的标准偏差来识别异常值。 当该比值过大时,该值即被定义为异常值。问题在于,标准偏差是根据所有值(包括异常值)计算得出的。当存在两个异常值时,标准偏差可能会变大,从而导致该比值降至用于定义异常值的临界值以下。参见掩蔽现象的示例。
建议
•如果您确信数据集中要么没有异常值,要么只有一个异常值,请选择 Grubbs 检验。
•若需考虑存在多个异常值的可能,请选择 ROUT 法。比较 Grubbs 法与 ROUT 法。
•请避免使用迭代格鲁布斯法。
•使用 Prism 绘制盒须图时,可选择显示 Tukey 须线,该功能会在数据点与中位数的距离超过四分位距(第 75 百分位数与第 25 百分位数之差)的 1.5 倍时,单独显示这些点。 有些人将这些点定义为异常值。我们在 Prism 中未实现这种异常值检测方法(除了创建盒须图之外),因为它似乎并未被广泛使用,且缺乏真正的理论依据。如果您希望我们加入这种异常值检测方法,请告知我们。
检测阈值应设多严格?
无法将异常值与高斯分布采样值彻底区分开来。总存在漏检真实异常值,或将某些“正常数据点”误判为异常值的风险。您需要自行决定异常值的判定阈值。具体选择会因所选的异常值检测方法而略有不同。
格鲁布斯检验 - 选择 α 值
在格鲁布斯检验中,您需要指定显著性水平α。这一概念与任何统计显著检验中的解读一致。若数据中不存在异常值,α即为错误地将某个数据点判定为异常值的概率。
请注意,α适用于整个实验,而非每个数据点。假设您将α设为5%,并对一个包含1000个数据点的数据集进行检验,所有数据均来自高斯分布。 将最极端的值识别为异常值的概率为 5%。这 5% 适用于整个数据集,无论其中包含多少个值。如果将 5% 乘以样本量 1000,并得出预期会识别出 50 个异常值的结论,那将是错误的。
Alpha 采用双侧检验,因为 Prism 中的 Grubbs 检验会识别出“过大”或“过小”的异常值。
ROUT方法 - 选择 Q
ROUT方法基于错误发现率(FDR),因此需指定Q值,即期望的最大FDR。
当不存在异常值(且数据服从高斯分布)时,Q 的解读与 α 相同。当所有数据均来自高斯分布(即不存在异常值)时,Q 即为识别出一个或多个异常值的概率。
当数据中存在异常值时,Q 即为期望的最大错误发现率。若将 Q 设为 1%,则意味着您期望被识别出的异常值中,虚假比例不超过 1%(实际上只是高斯分布的尾部),从而确保至少 99% 的被识别异常值确实属于异常值(来自不同的分布)。 若将 Q 设为 5%,则预期被识别出的异常值中,虚假比例不超过 5%,且至少 95% 的被识别异常值是真实的。
建议
这种权衡关系很明确。如果将 alpha 或 Q 设得太高,那么许多被识别出的“异常值”实际上只是从与其他数据点相同的高斯分布中采样而来的数据点。如果将 alpha 或 Q 设得太低,则无法识别出所有异常值。
目前尚无关于异常值识别的统一标准。我们建议您从将 Q 设为 1% 或 alpha 设为 0.01 开始。
Prism 如何呈现结果
结果分三页展示:
•已清理数据(已移除异常值)。您可以将此页面作为其他分析(如 t 检验或单因素方差分析)的输入。
•仅异常值。
•摘要。此页面列出了每个数据集中检测到的异常值数量。