对整行或数据集的每一列分别进行计算
为整行计算一个均值、中位数等
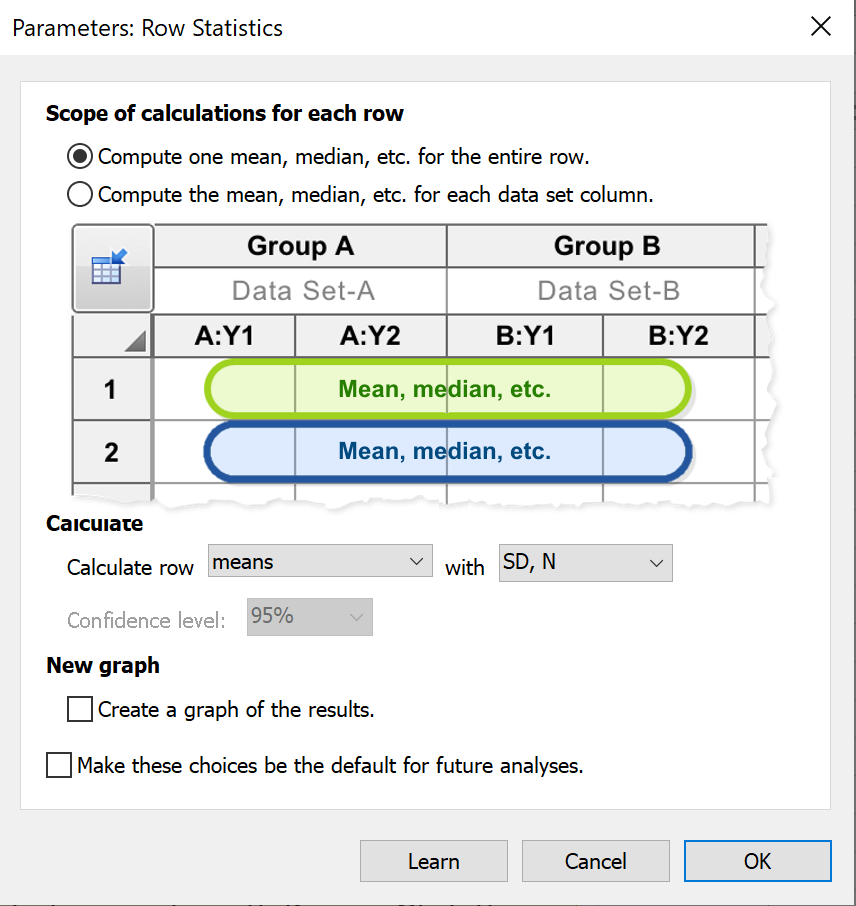
如果数据仅输入到表中的单个数据集中,或者每个数据集仅包含一个子列,那么 Prism 将如何执行所选计算不会产生模糊拟合。但是,当数据输入到多个数据集中,且每个数据集都包含多个子列时,Prism 会基于每个数据集的总和/均值/中位数等,分别计算该行的汇总结果。 例如,假设您选择为分别包含 3、2 和 3 个重复数据的三个数据集计算“行均值及标准差”。第一行数据可能如下所示:
数据集 A:{2, 3, 4}
数据集 B:{4, 6}
数据集 C:{7, 8, 9}
Prism 首先会计算每个数据集的平均值,即 3、5 和 8。然后,它会计算这三个值的总体平均值(以及相应的标准偏差),因此该分析的结果为:平均值 = 5.333,标准偏差 = 2.517,样本量 = 3。
如果 Prism 仅仅将这八个值视为独立数据,则会计算出均值 = 5.375 和标准差 = 2.504。然而,由于不同数据集中的值不太可能相互独立,Prism 不会进行此项计算。
计算每个数据集列的均值、中位数等
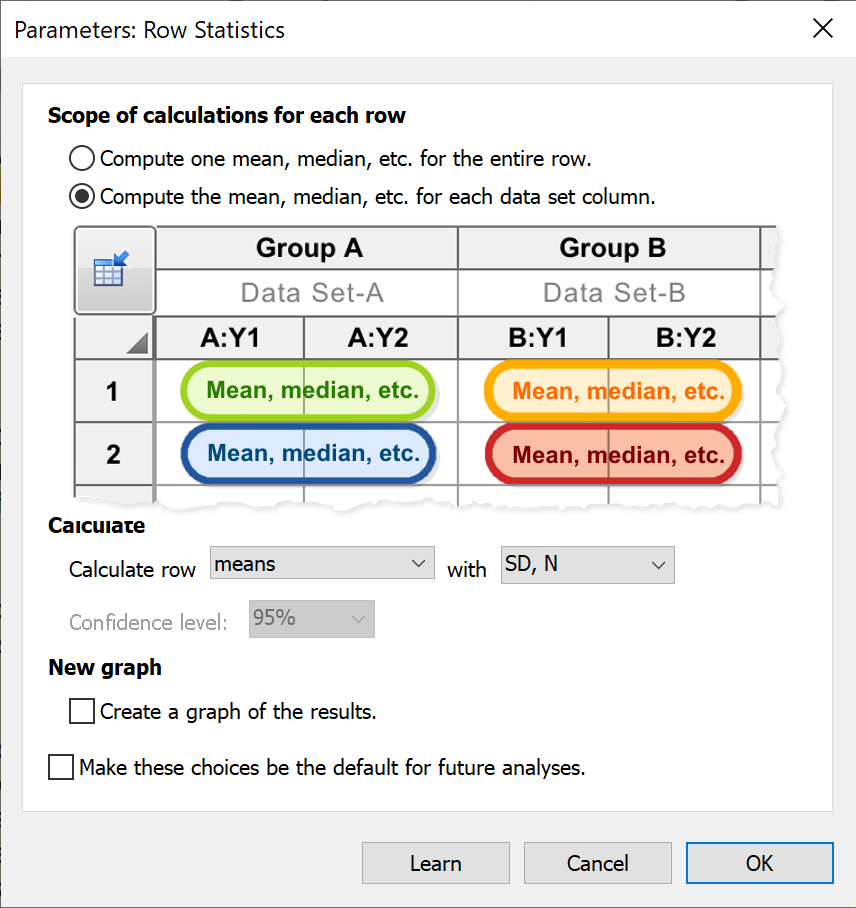
当数据输入到包含子列的数据集时,此选项将指示 Prism 为每个数据集内的每一行分别计算平均值(或中位数、总和等)。 请注意,您无需手动执行此分析即可绘制数据的均值或误差图,因为 Prism 在创建数据图表时会自动处理此操作(您可以通过“设置图表格式”对话框指定 Prism 应显示单个数据点,还是显示标准差、标准误、95% 置信区间或范围的误差条)。 此分析的主要目的仅在于生成包含这些汇总值(均值、中位数等)和误差值(标准差、标准误等)的表格。
指定所需的计算
选择要计算的行:
•总计
•均值
•中位数
•几何均值
根据所选的计算值,请额外选择如何报告计算误差:
计算 |
误差选项 |
总计 |
无 |
均值 |
•不计算误差 •标准差,样本量 •标准误差,样本量 •%CV,N •置信区间 (CI) |
中位数 |
•未计算误差 •四分位数 •最小值/最大值 •百分位数 |
几何均值 |
•不计算误差 •几何标准差 •置信区间 (CI) |
选择“置信区间”或“百分位数”作为误差选项,可让您为这些计算指定所需的置信水平或百分位数。
创建结果的新图表
选择此选项时,Prism 将自动生成一个包含计算结果(及相应误差值)的新图表