什么是残差?
未加权拟合
残差是指数据点与曲线的距离。最小二乘回归旨在使这些残差平方和最小。当数据点位于曲线上方时,残差为正;当数据点位于曲线下方时,残差为负。绘制残差图可直观了解数据与所选模型的拟合程度。相较于数据与曲线的合图,残差图往往更容易发现数据与模型之间的轻微偏差。
加权拟合
如果您选择对数据进行不等权重处理,Prism 将相应调整残差的定义。
Prism 所计算并绘制的残差等于前一段定义的残差除以加权因子。最常见的替代权重方法是“按 1/Y² 加权(最小化相对距离的平方)”。在此情况下,残差被定义为数据点到曲线的距离除以曲线的 Y 值。 加权非线性回归旨在最小化这些残差平方和。请注意权重定义中的歧义。Prism 对话框提供按 1/Y² 加权的选项。这意味着残差平方除以 Y²。加权残差定义为残差除以 Y。加权非线性回归旨在最小化这些加权残差的平方和。
Prism 的早期版本(至 Prism 4 为止)始终绘制基本的未加权残差,即使您选择对数据点进行不等权重处理也是如此。
哪种残差图?

Prism 提供了五种可用于分析模型拟合残差的图表:
X 轴 |
Y 轴 |
|
残差图与 X 坐标图 |
数据的 X 值 |
残差或加权残差 |
残差图与Y坐标图 |
预测的 Y 值 |
残差或加权残差 |
同方差性图 |
预测的 Y 值 |
残差或加权残差的绝对值 |
QQ图 |
实际残差 |
若残差采样自高斯分布,则为预测残差 |
实际值与预测值散点图 |
实际 Y 值 |
预测 Y 值 |
Prism 允许您根据非线性回归生成任意数量的残差图。只需勾选您希望包含在分析结果中的残差图名称旁边的复选框即可。
示例
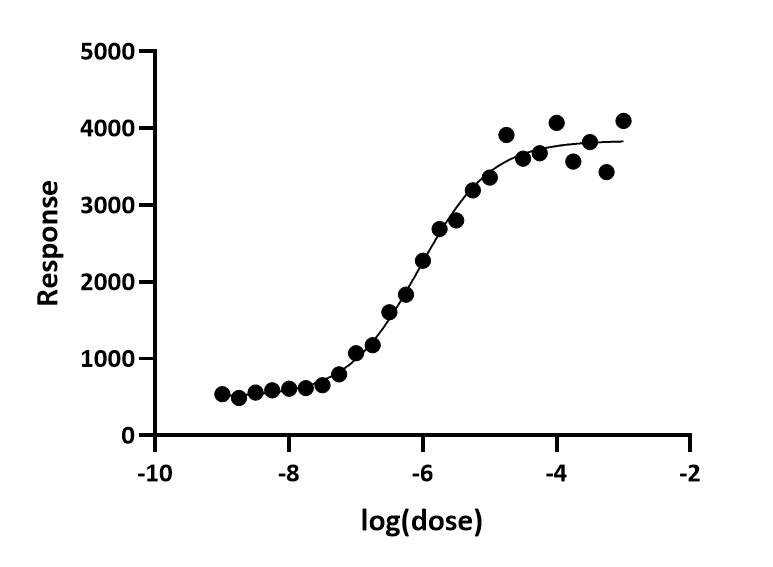
拟合示例
这是一条基于模拟数据的对数剂量(log(dose))与剂量反应曲线。随机散布的设置使得 Y 值较大的数据点具有更大的平均散布。拟合采用常规方法进行,未进行加权处理。若仔细观察,您会发现曲线顶部的数据点散布更明显,但这种差异并不十分显著。
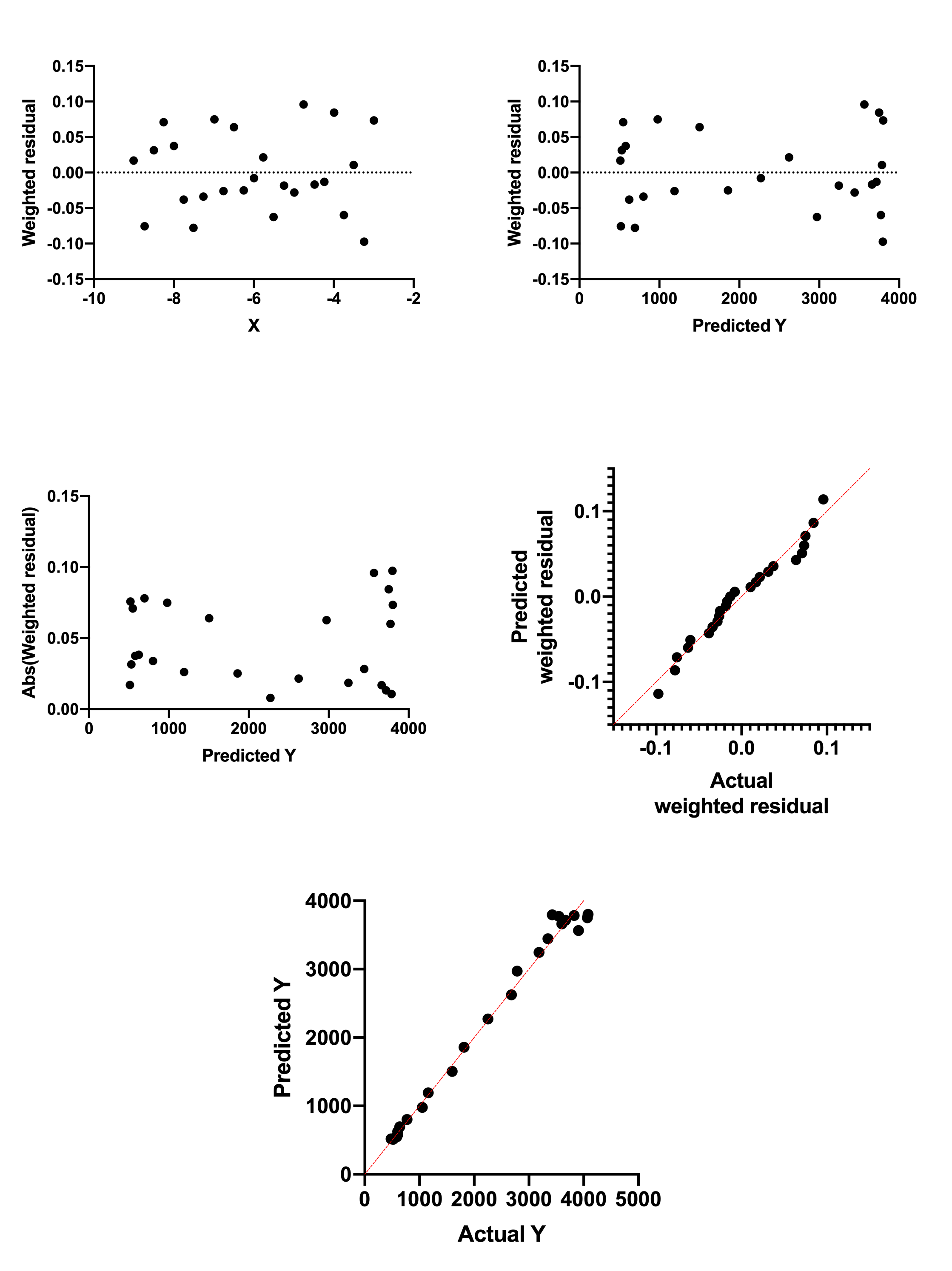
残差与 X 值
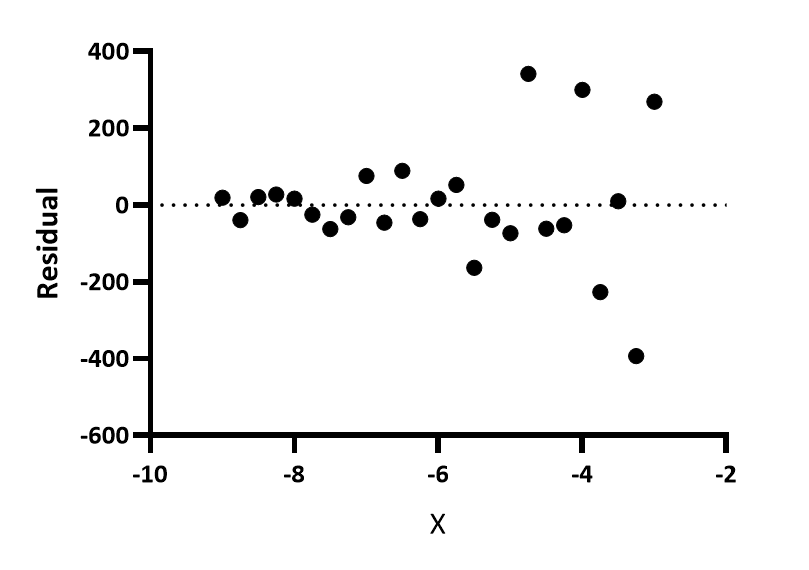
这是最常见的残差图。Prism 7及更早版本仅生成此类残差图。您可以观察到,X值较大的数据点具有更大的残差(正值和负值)。
残差与预测 Y 值
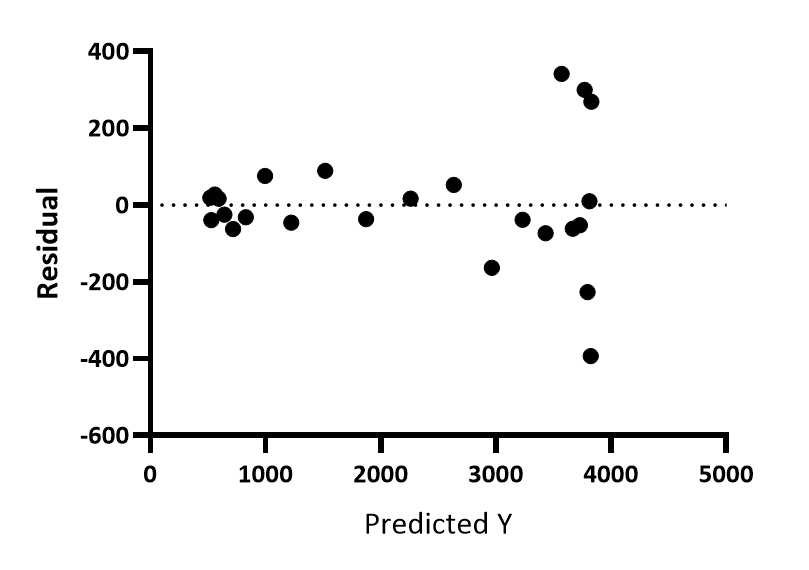
对于每个数据点,Prism 会计算该 X 值处曲线的 Y 值,并将该 Y 值绘制在残差图的 X 轴上。残差图的 Y 轴则绘制残差或加权残差。可以看出,Y 值较大的数据点其残差(无论是正值还是负值)也较大。
在本示例中,随着 X 值增大,Y 值也随之增大。因此,该图与残差图看起来差异不大。但如果曲线呈双相分布,这两张图的差异将更为明显。
同方差性图
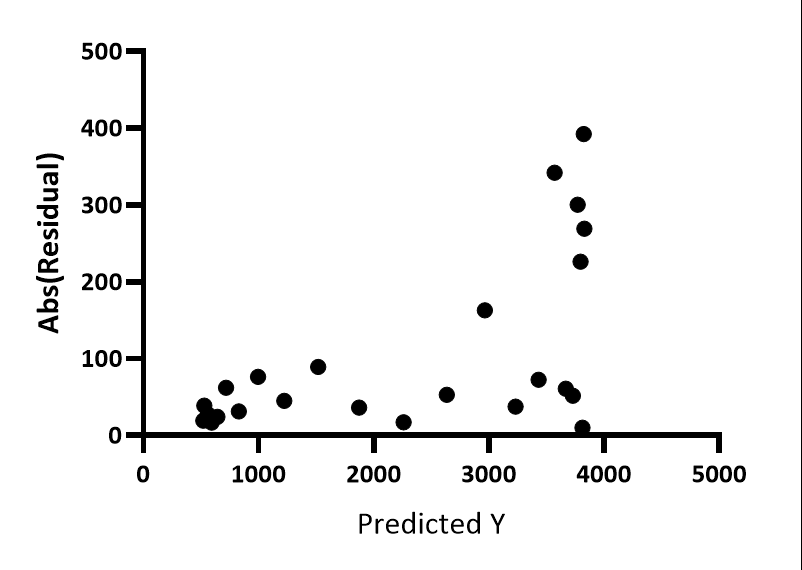
该图的绘制方法与“预测 Y 值与残差”图完全相同,只是这里显示的是残差的绝对值。现在可以非常清楚地看到,随着 Y 值增大,残差也随之增大。
QQ图
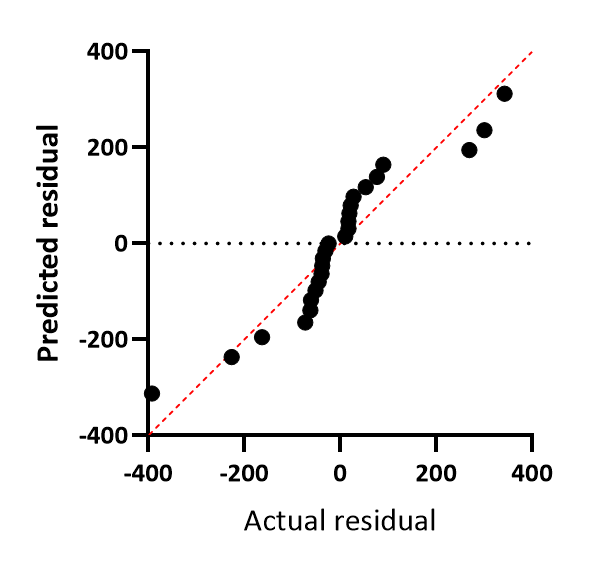
X 轴绘制实际残差或加权残差。Y 轴绘制假设残差服从高斯分布时的预测残差(或加权残差)。 回归分析的一个假设是残差服从高斯分布,该图可用于检验这一假设。若假设成立,所有数据点应非常接近图中用红色标出的单位线。QQ图有时会将一个或两个坐标轴绘制为百分位数或分位数(与百分位数相同,但以分数形式而非百分比表示)。Prism始终将两个坐标轴的单位设置为与数据Y值的单位一致。
在本示例中,数据与单位线的吻合度较差。虽然数据采样自高斯分布,但当 Y 值较大时,该分布的标准差也随之增大。残差并非采样自单一高斯分布,这正是数据点与单位线之间存在系统性偏差的原因。
实际值与预测值图
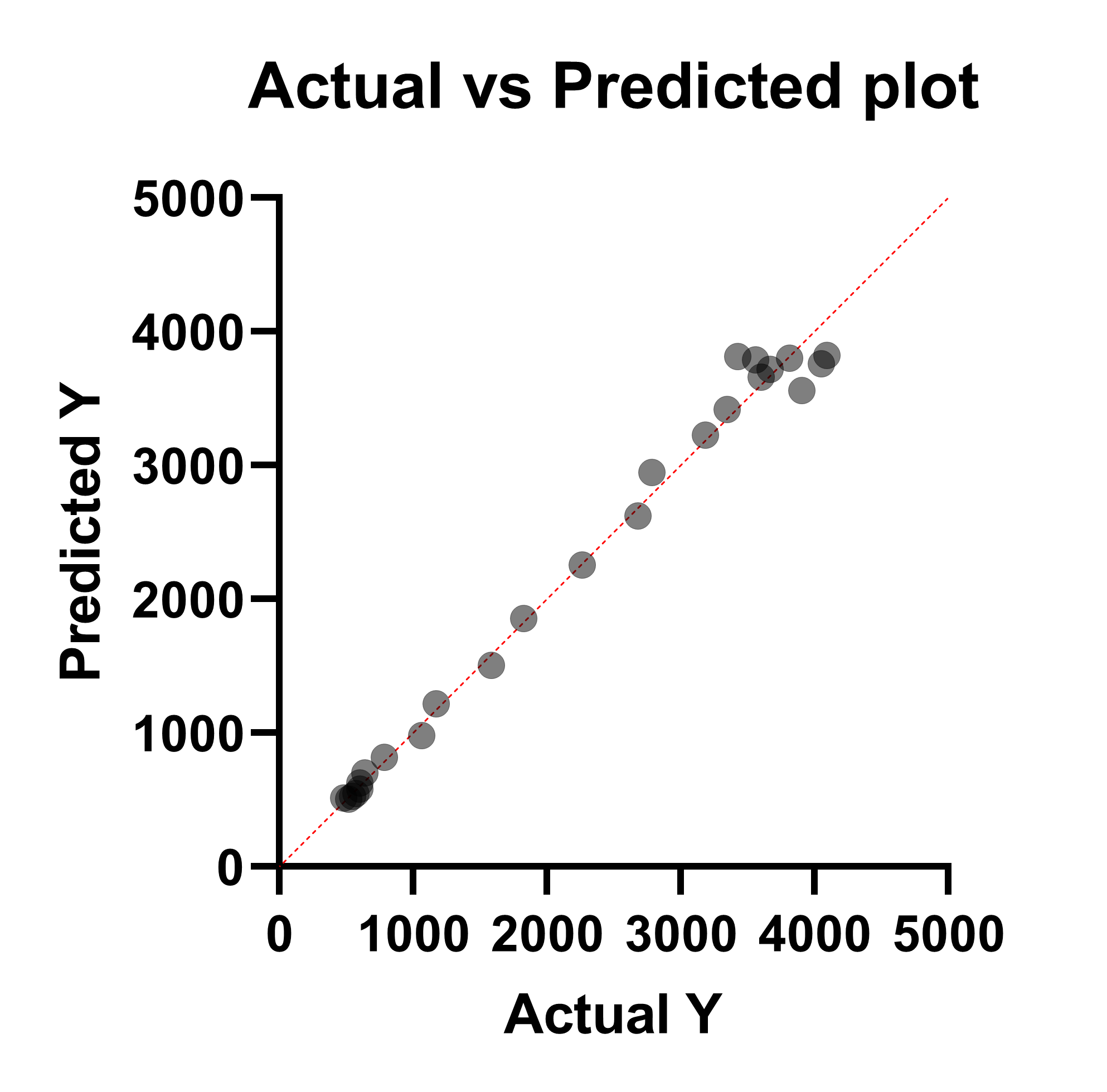
该图并未在任一坐标轴上直接绘制拟合残差。相反,该图在 X 轴上绘制实际 Y 值(在数据表中输入的值),在 Y 轴上绘制预测 Y 值。此图常用于评估简单线性回归的拟合情况(Prism 也会为多元线性回归生成此图),但在非线性回归中并不常见。 在此情况下,残差由绘制点与红色恒等线之间的垂直距离表示(也可使用水平距离,因为对于每个点,这两种距离始终相等)。
尽管在非线性回归中使用此图并非标准做法,但它仍可作为评估模型对测量结果(因变量)预测精度的手段。上图显示:在较低的 Y 值范围内,模型对实际值的预测效果更好(数据点更接近单位线);而在较高的 Y 值范围内,预测值与实际值的偏差增大(数据点远离单位线)。
然而,必须注意的是,仅因模型对数据的预测效果极佳(换言之,曲线与每个数据点非常接近),并不意味着该模型是正确的!在非线性回归中,只要包含足够的项,便能生成一条几乎完美地通过每个数据点的任意曲线。在尝试解读此图之前,请务必确保您所使用的模型在科学上具有合理性。
使用加权回归拟合的示例
随后,将数据拟合到相同的模型中,但采用了相对权重。以下是五张残差图。所有图均表明,数据现已符合拟合的假设。