与简单线性回归类似,简单逻辑回归试图为一组参数找到最佳拟合值。然而,与简单线性回归不同的是,简单逻辑回归是通过一种迭代过程来寻找最佳拟合值的:该过程从这些参数的初始值开始,一步一步地向最佳拟合值靠近。正因如此,对于某些数据集,该迭代算法无法计算出这些最佳拟合值。 此时,Prism 会显示一条错误信息,指出数据中可能存在“完全分离”问题,或者仅有一个 X 值。
确定控制数据的过程所涉及的数学概念(以及该过程中可能出现的错误)在简单逻辑回归和多元逻辑回归中是相同的。下文将对简单逻辑回归中出现此错误信息的原因进行非常基础的解释。关于模型拟合过程及可能出现的错误的更详细说明,请参见多元逻辑回归的相应页面。
完全分离
“分离”这一概念适用于当X变量的值能完全预测Y变量值的数据集。换言之,对于数据集中的每个观测值,当X小于某个特定值时,Y将呈现一种结果;而当X大于该值时,Y将呈现相反的结果。以下数据即为完美分离的一个示例:
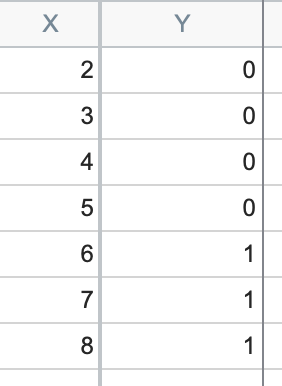
在上方的数据集中,当 X 小于或等于 5 时,所有 Y 值均为 0;而当 X 大于 5 时,所有 Y 值均为 1。由于数据无法提供任何线索来预测当 X 为 5.1、5.5 或 5 到 6 之间的任何值时会产生何种结果,因此无法拟合 S 形的逻辑曲线。
当数据未“完美”分离时,会出现一个密切相关的问题,例如在以下数据集中:
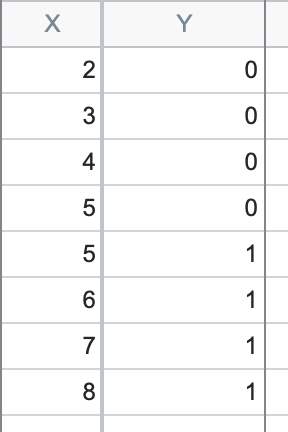
在此,您可以看到当 X 值小于 5 时,Y 为 0;当 X 值大于 5 时,Y 为 1。但在 X = 5 时,我们同时观察到了 Y = 0 和 Y = 1 的情况。这是分离性的一种特例,称为“准完美分离”。
仅存在单一 X 值
简单逻辑回归的目标是根据预测变量(X变量)的值,预测“成功”(Y = 1)的概率。然而,如果所有观测值的预测变量值都相同,就无法拟合一个将“成功”概率作为该预测变量函数来预测的模型。
从数学角度看,这一问题是由 β0 与 β1 之间的线性依赖度引起的。当模型包含多个预测变量时,多变量逻辑回归中也会出现类似问题。