重要结果
P值
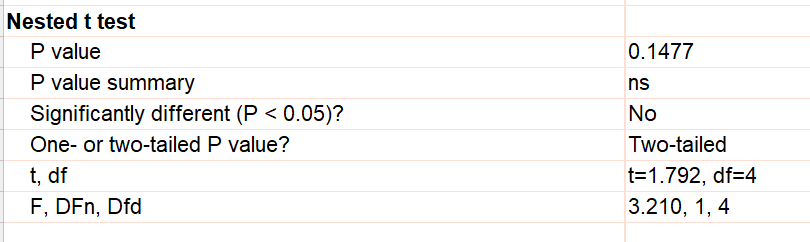
结果的呈现方式与非配对t检验类似。P值用于检验“两个处理组的均值相等”这一零假设。P值既可以通过t比值(与非配对t检验对应)计算,也可以通过F比值计算(因为此类数据通常采用嵌套方差分析进行分析)。 t 比值是 F 比值的平方根(因为分母自由度 df 为零),因此无论采用哪种方法,P 值都是相同的。我们同时展示这两种结果,以便您能与其他程序或文献进行对照
置信区间

最重要的结果是两个均值差的95%置信区间。若您有需要,可在对话框中选择90%或99%置信区间。
其他结果(大多数科学家会忽略)

嵌套 t 检验拟合的是混合模型。之所以称为混合模型,是因为子列中堆叠的值以及子列的选择被假设为随机,而处理(本示例中为教学方法)是固定的。这意味着我们关注的是这两种教学方法的比较,但学校的选择以及学校内的学生分配是随机的。我们并不关心那些特定的学生或特定的学校。 该模型拟合了子列内部和子列之间的变异,并分别以方差和标准偏差(即方差的平方根)的形式报告这些结果。Prism 报告这些数值以便您与其他程序或文献进行比较。这些数值本身并不太有帮助。
您将学生分配到不同的子列中,是因为您预期不同教室的结果会有所不同。Prism 检验的零假设是:实际上,同一列(教学方法)内的所有子列(学校)都是相同的。此处的 P 值为 0.0027,因此您可以拒绝该零假设。此检验的实用价值有限。
Prism 会可选地报告 REML 拟合优度值,以便与其他软件和教材保持一致。试图解读该值毫无意义。