实验设计
您分别对对照组和处理组的大鼠测量了一个变量。每组有三只大鼠,每只大鼠测量了四个技术重复。请注意,每子列中堆叠的四个数值顺序是任意的。这四行数据没有时间序列关系,其顺序也没有其他特殊含义。
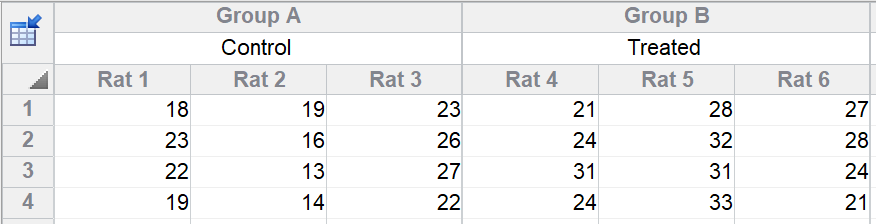
为什么这是嵌套设计?
该设计被称为嵌套设计,是因为每只大鼠要么属于对照组,要么属于处理组。您无法判断某些大鼠对治疗的反应是否优于其他大鼠,因为每只大鼠仅接受其中一种替代性处理。因此,大鼠被视为嵌套在处理组内。
这也被称为分层设计。分层和嵌套是描述此类设计时的同义词。
错误分析:对所有数据进行t检验
虽然将这些数据视为每组样本量为 n=12 很有诱惑力,但这种做法并不恰当。
若对这些数据进行 t 检验,均值差的 95% 置信区间为 3.2 至 10.5,且检验“样本来自均值相同的总体”这一零假设的双侧 P 值为 0.0008。这似乎是治疗增加了因变量的有力证据。但这些结果并无实际意义。
为什么?因为t检验假设每个数据点都提供独立的信息。虽然每种处理组都有三只独立的大鼠,但并没有十二个独立的结局测量值。 同一只动物的重复测量值彼此之间的距离,比与其他动物测得的值之间的距离更近。换言之,当您将三只大鼠的重复测量值与每只大鼠内的四个技术重复测量值合并时,所得的12个值实际上是伪重复。若将伪重复当作真正的重复进行分析,会导致置信区间过窄,P值过小。
错误分析:双因素方差分析
本页顶部所示的数据看似适合进行双因素方差分析。 但执行双因素方差分析会导致错误或误导性的结果。双因素方差分析会假设第2行数据所对应的鼠类在某种程度上同时暴露于对照组和处理组条件下。但实际上,每个子列中值的顺序是任意的,因此将行作为“因子”在双因素方差分析中进行检验是毫无意义的。
不使用嵌套t检验的替代分析方法(仅在样本量相等时适用)
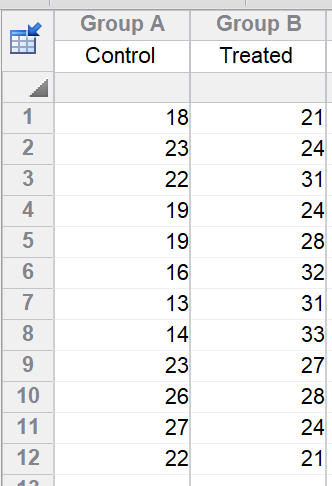
若无缺失值,可采用 t 检验分析数据。第一步是计算每只大鼠的技术重复平均值。随后将这些均值填入新表格,再通过非配对 t 检验比较两组均值。需注意:在 t 检验中,每组的三只大鼠数据被堆叠在同一列中;而在嵌套 t 检验中,它们则并列于各子列中。
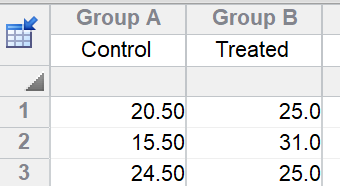
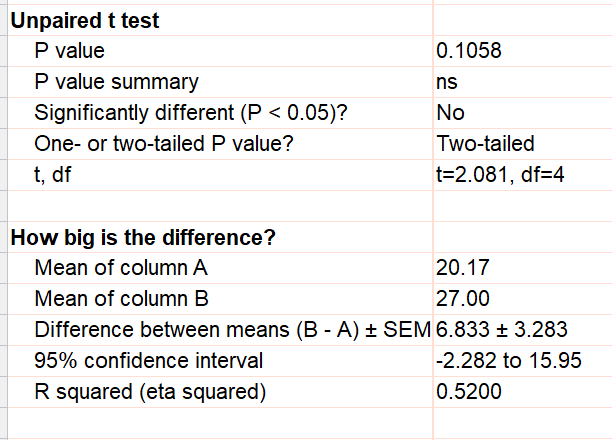
只要没有缺失值,这将得出正确的结果。根据这一正确结果,差异的95%置信区间为-2.3至15.9,P值为0.1058。请注意,此处的结论(无证据表明存在治疗效应)与通过分析伪重复数据得出的错误结论截然不同。
Prism 中的嵌套 t 检验
Prism 8 引入了一项新分析功能 - 嵌套 t 检验,该功能可一步完成分析并能处理缺失值。它假设子列均值是从子列均值的高斯总体中抽样的,且子列内的重复数据是从高斯总体中抽样的。这两个高斯总体通常具有不同的标准偏差,Prism 会计算(估计)两者,并分别以标准偏差(SD)和方差的形式报告。