1. 创建数据表
在“欢迎”或“新建表格”对话框中,选择创建 XY 数据表。请务必勾选“为每个数据点输入并绘制单个 Y 值”选项。Prism 中的简单逻辑回归目前不支持在子列中输入重复数据。若需输入重复数据,只需将每个重复数据与相应的 X 值和观察值分别添加到单独的行中即可。
若想查看 Prism 在示例数据集上的运行效果,请选择示例数据:简单逻辑回归。否则,若要输入自有数据,请确保 Y 值为二元变量,且严格编码为 0 和 1。若因变量未编码为 0 和 1,Prism 将无法执行简单逻辑回归(或多元逻辑回归)(阅读更多关于二元因变量的信息)。
提示:区分哪些结果编码为 1、哪些编码为 0 的简便方法是将 Y 列标题设为“是/否”问题。采用此方法,您可输入“1”表示“是”,输入“0”表示“否”。
2. 分析选项
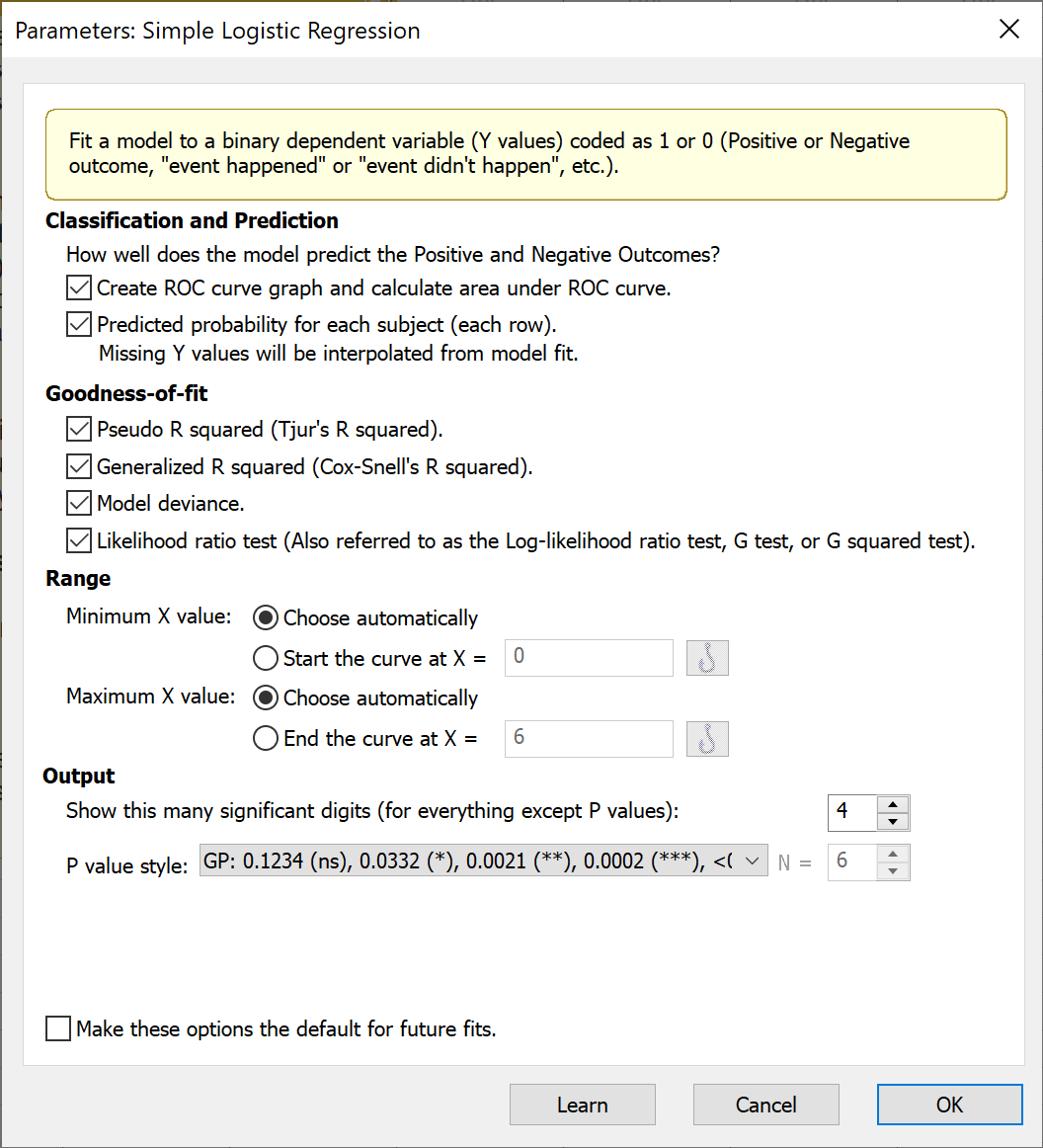
要运行简单逻辑回归,请点击工具栏中的“分析”按钮,并在 XY 分析列表中选择“简单逻辑回归”。简单逻辑回归的参数对话框提供了多种自定义选项。若需更多分析选项,建议将数据复制到多变量数据表中,并使用多变量逻辑回归分析。
a. 分类与插值
本节中的选项提供了有关模型在预测阳性与阴性结果(在数据中分别输入为 1 和 0)方面的表现信息。 您可以要求 Prism 生成 ROC 曲线,并在结果表中报告 ROC曲线下面积 (AUC)。AUC 反映了逻辑回归模型在各种可能的阈值下对观测数据的分类效果。如需进一步了解 ROC 曲线,请参阅此页面。
选择“每个受试者的分类”将生成一个名为“行分类”的新绿色表格,该表格首先复制观察值的列,并添加一列,其中包含简单逻辑回归模型对每个观察值预测的概率。 请注意,您可以使用此选项对特定 X 值进行新观测值的预测。操作时,只需在原始数据表底部添加一行,填写所需的 X 值(或多个值),并将对应的 Y 值留空(请注意,此过程与简单线性回归中的插值方法非常相似,但无需选择额外选项即可自动完成)。
b. 拟合优度
除了分类性能外,Prism 还提供了四种评估模型性能的方法。
评估线性模型拟合度的标准指标是 R 平方。然而,由于简单逻辑回归模型并非采用与简单线性回归相同的技术进行拟合,因此该指标不适用于逻辑回归。 对于简单逻辑回归,Prism 提供了两个替代 R² 的指标。尽管这些指标名称中包含“R²”一词,但其含义与简单线性回归中的 R² 并不相同(即它们并不代表模型解释的方差比例)。
相反,Tjur 的伪R平方和 Cox-Snell 的广义 R 平方都是介于 0 到 1 之间的数值,数值越大表示模型的预测性能越好。有关这些伪R平方指标(以及通过多变量数据表中的多元逻辑回归提供的其他指标)的更多详细信息,请参见此处。
模型偏差会产生一个有时被称为 G² 的值,该值用于计算似然比检验的检验统计量。如果您正在比较模型中不同的 X 预测因子,可以选择导致模型偏差最小的那个预测因子。您也可以以同样的方式使用伪R平方和广义 R² 值。
似然比检验(LRT)将包含给定 X 预测因子的逻辑回归模型与不包含该 X 预测因子的模型(即“仅截距模型”)进行比较。与其他假设检验一样,LRT 采用零假设,并生成 P 值来检验该零假设。 在此情况下,零假设是“仅截距模型”(不含 X 变量的模型)比包含 X 变量的模型更适合数据。如果您的 X 变量有助于提升模型的预测性能,则该检验的 P 值预计会较小。
c. 范围
执行简单逻辑回归时,系统会自动生成逻辑曲线图。您可以让 Prism 根据您的数据自动选择绘制该曲线的默认最小和最大 X 值,也可以根据需要自行调整这些限值。