引言
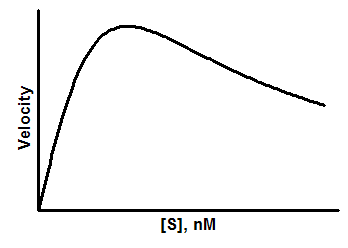
在高浓度下,某些底物也会抑制酶的活性。约20%的已知酶会发生底物抑制现象。当两分子底物能够与酶结合,从而阻断其活性时,就会发生这种现象。
分步操作
创建一个XY数据表。在X列中输入底物浓度,在Y列中输入酶活性。如果有多个实验条件,将第一个条件置于A列,第二个置于B列,依此类推。
输入数据后,点击“分析”,选择“非线性回归”,选择“酶动力学方程”面板,并选择“底物抑制”。
模型
Y=Vmax*X/(Km + X*(1+X/Ki))
参数
Vmax 是酶的最大反应速率(假设底物未抑制酶活性),其单位应与 Y 相同。
Km 是米氏常数,单位与 X 相同。它描述了在无抑制剂存在时底物与酶的交互作用。
Ki 是底物结合的解离常数,表示两个底物可以结合到一个酶上。其单位与 X 相同。
注:Prism 7 及后续版本采用的初始值规则与 Prism 6 不同(已改进)。
为何该模型不总能收敛到拟合结果
若将该模型重新排列,则更容易理解拟合时的问题:
Y=Vmax/(Km/X + 1 + X/Ki)
Vmax 控制峰值高度(但不等于峰值处的 Y 值)。
当 X 值较小时,最后一项趋近于零,因此曲线的早期部分(小 X 值)由 Km 的值决定。
反之,当 X 值较大时,第一项趋近于零,因此曲线的后半部分(较大 X 值)由 Ki 的值决定。
曲线的中间部分由 Ki 和 Km 共同决定。
拟合结果会导致“模糊拟合”的情况,主要有两个原因。
•X 值范围的数据点不够广泛。需要有小于 Km 和大于 Ki 的 X 值,理想情况下应有大量的 X 值。如果您只有曲线中间的数据,那么就根本没有信息来分别确定 Km 和 Ki。
•虽然曲线形状看起来像底物抑制曲线,但实际上并不完全正确。换句话说,这些数据实际上并不符合底物抑制模型。