有些程序会在非线性回归结果中报告卡方检验值,但Prism不会。本页将解释卡方检验值有何用处,以及我们为何不报告该值。
平方和是否过高?
非线性回归旨在最小化数据点与曲线之间垂直距离的平方和。但如何解读平方和(简称 SS)呢?实际上很难直接解读,因为它依赖于您收集的数据点数量以及用于表示 Y 的单位。
卡方法的核心在于将数据点围绕曲线的实际离散程度(SS)与理论预期中的实验离散程度进行比较。具体通过以下公式计算卡方检验值:
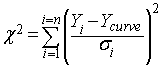
卡方检验值等于各数据点到曲线的距离与该X值处预测标准偏差之比的平方和。请注意,分母是预测标准偏差,而非本次实验中计算出的实际标准偏差。
若已知所有X值对应的标准差(SD)均相等,则可简化为:
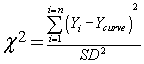
标准偏差必须基于大量数据计算,以确保其高度精确。或者,更理想的情况是,标准偏差可由理论推导得出。
若假设重复测量数据点遵循高斯分布(标准差即为输入值),且数据拟合模型正确,则根据该公式计算出的卡方检验值将服从已知的卡方检验分布。该分布依赖于自由度,其数值等于数据点数减去参数数。已知卡方检验值和自由度后,即可计算出P值。
如何解读较小的P值?如果您确信数据点确实服从高斯分布,且预测的标准差是正确的,那么较小的P值表明您的模型不正确 - 曲线实际上与数据吻合得并不理想。您应该寻找一个更好的模型。
但通常情况下,较低的 P 值仅仅表明您对标准差的预测不如预期准确。由于难以精确确定标准差值,因此也难以准确解读卡方检验值。正因如此,Prism 并未尝试进行卡方检验计算。我们担心这会带来更多误导,而非提供帮助。
替代方案
为解答“平方和是否过高”这一问题,已提出几种方法:
•可利用平方和计算 R²。该值通过将平方和(衡量数据点围绕曲线的离散程度)与 Y 值的总变异量(忽略 X 变量及模型)进行比较来计算。您期望得到什么样的 R² 值?多低的值才算过低?这个问题无法一概而论,因为答案依赖于您的实验系统。
•如果您在每个 X 值处都收集了重复的 Y 值,您可以将 SS 与根据重复样本间的离散程度预测出的值进行比较。Prism 将此称为重复样本检验。这非常有用,但前提是您必须在每个 X 值处都收集了重复的 Y 测量值。
•您可以提出替代模型,并比较它们对数据的拟合情况
总结
卡方检验将数据与曲线之间的实际偏差,与基于已知重复测量标准差(SD)计算出的预期偏差(假设您选对了所选模型)进行比较。如果偏差较大,则表明您可能选错了模型。卡方计算的优势在于,它能检验单一模型的适用性,无需提出替代模型,也无需重复测量数据。 其缺点在于,该计算的依赖度在于对标准差值的精确掌握,而现实中往往难以满足这一条件。
建议的替代方案是比较两个模型的拟合情况,或使用重复测量检验。