“Cox比例风险回归分析参数”对话框中的“图表”选项卡用于生成图表,以直观展示特定组别随时间变化的估计生存概率。需要注意的是,这些估计生存曲线是根据分析中定义的“模型”生成的,并不代表通过选取数据进行 Kaplan-Meier 生存分析所生成的生存曲线。 相反,这些生存曲线是基于Cox回归的一个关键假设生成的:即任何个体(或由一组预测变量定义的个体群体)的危险率与某种基线危险率成正比。 这一假设的必然结果是,所有估计的生存曲线都将具有相同的基本形状(包括它们都在相同的时间点出现“阶梯”)。这是因为每条估计的生存曲线都是基于基线生存率(本页已讨论)计算得出的。对于具有特定预测变量集的给定个体/组而言,其估计生存率与基线生存率之间的关系可表示为:
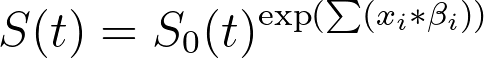
该方程可不使用参数估计值,而改用各预测变量的风险比来重写:
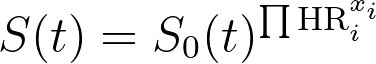
本质上,这意味着对于给定的个体或组(模型中预测变量的取值已指定),其在所有时间点的估计生存率将相对于基线生存率呈比例性增高或降低。改变预测变量的数值不会改变估计生存曲线的整体形状,只会改变新估计生存曲线与已确定的基线生存曲线之间的比例关系。
在指定 Prism 生成估计生存曲线时应使用的预测变量时,有两个概念需要牢记:
•若未指定某个预测变量,则生成估计生存曲线时将假设该变量取其基线值
•Prism 将自动确定所有已指定预测变量值的可能组合,并针对每种组合生成相应的估计生存曲线
考虑一个将年龄作为连续预测变量(且未先对数据进行中心化处理)的模型。该变量的基线值为零(因为它是连续变量)。 在生成估计生存曲线时,如果未指定年龄的数值,生成的曲线将代表年龄为零时的估计生存情况。在大多数情况下,这可能没有太大意义(例如,体重或身高为零的情况也是如此)。因此,如果模型中某个连续变量被识别为重要的预测变量,在指定估计生存曲线时,应考虑包含该变量的数值。
当使用分类变量指定估计生存曲线时,可能存在多种不同的水平组合来定义不同的组别。考虑两个分类变量:
•性别,两个水平“女性”和“男性”
•治疗组(Treatment_Group),三个水平:“对照组”、“标准治疗”和“实验治疗”
利用这两个分类变量,可以定义六个不同的组:
1.对照组中的女性
2.标准治疗组中的女性
3.实验治疗组中的女性
4.对照组中的男性
5.标准治疗组的男性
6.实验治疗组的男性
无需手动定义这六种组合,只需在参数对话框中选择两个变量(并为每个变量选择相应的水平),Prism 就会自动确定绘图所需的独立估计生存曲线数量。 在本示例中,若添加第三个变量“血糖浓度”(水平为“低”、“中”和“高”),组合总数将增至 18 个。但使用 Prism 时,您只需选择这三个变量(及其水平),而无需手动指定全部 18 种不同的组合。