参数估计
您首先看到的结果部分是指定模型中回归系数(β系数)的最佳拟合值。请注意,与其他一些多元回归技术不同,Cox比例风险回归不包含截距项(β0)。即使强行将截距项纳入模型,它也会被基线风险(h0(t))所“吸收”。 此外,请注意,当模型中包含分类变量时,这些变量会自动进行“虚拟编码”,从而导致除参考水平外,分类变量的每个水平都会产生独立的参数估计值。因此,如下所示,本模型的结果包含十三项独立的β系数:
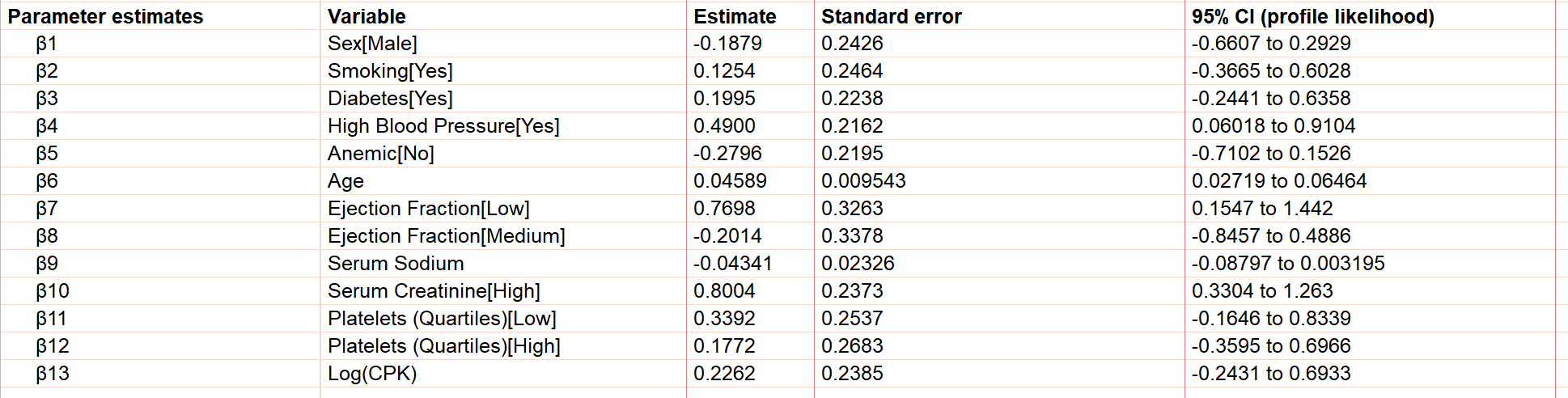
这些参数估计值的解读与标准多元线性回归略有不同。请考虑本分析所采用的Cox比例风险回归模型:
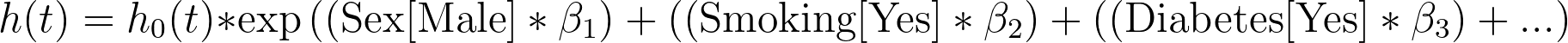
若通过除以基线风险对该方程进行重排,可得如下形式:
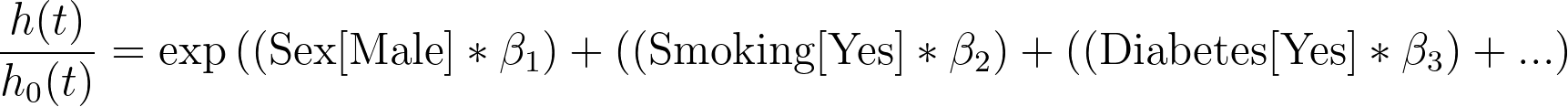
最后,若对等式两边取自然对数,则得到如下形式:
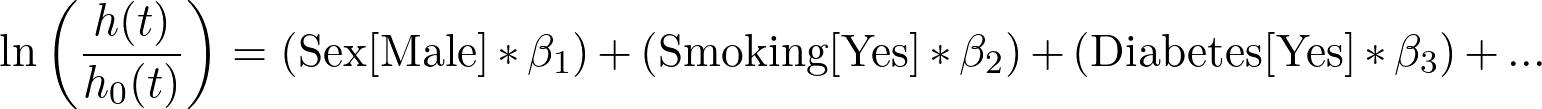
利用这种方程形式,现在可以看出,方程左侧是特定个体或群体(使用与其对应的特定预测变量)的风险比,除以基线危险率(代表所有预测变量设为零或其参考值时的危险率)的对数。 “比例风险”这一术语的由来正源于此,因为本分析中的模型实际上是在估计风险比(由不同预测变量指定的组与基线组之间的比值)。
基于此,我们可以看出β系数的数值代表对数危险率的增加(正值)或减少(负值)。例如,在我们的结果中,β1(性别[男性])等于-0.1879。这意味着与女性相比,男性的对数危险率在所有时间点上均降低了0.1879。 β6(年龄)的值为0.04589。这意味着个体的年龄每增加一岁,对数危险率就会增加0.04589。
风险比
β系数的直接解读较为复杂,因为它们对应的是对数危险率的变化,而通常人们更容易理解线性尺度上的变化,而非对数尺度。因此,结果部分的下一节将介绍风险比。
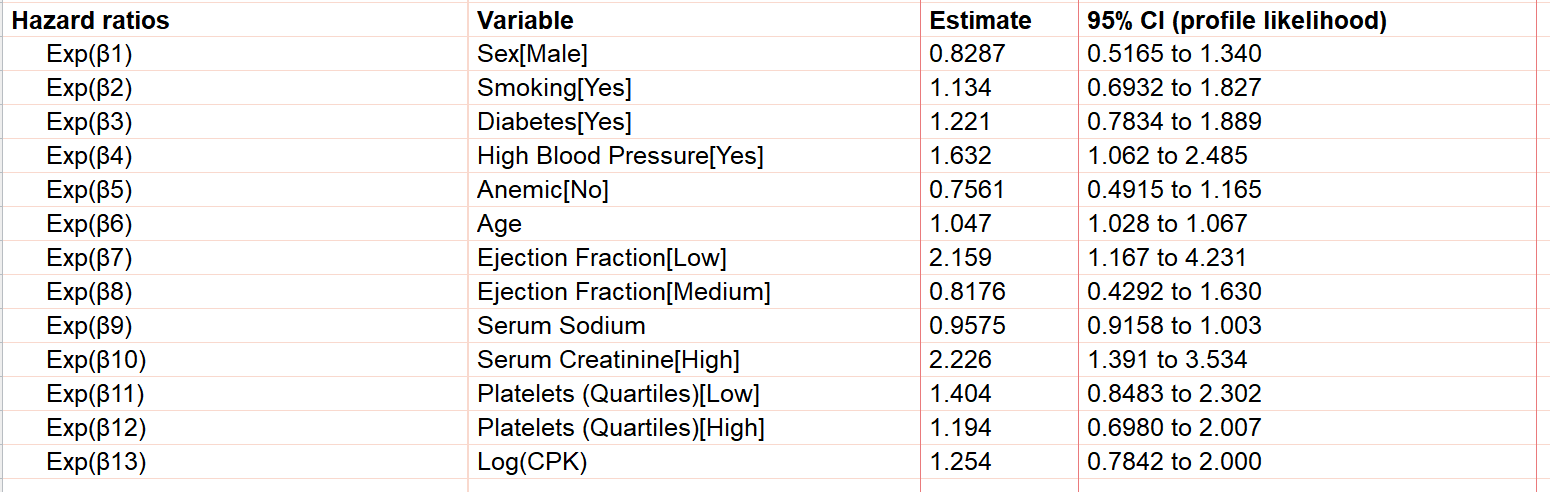
关于参数估计值与风险比之间关系的更详细讨论可参见此处,但本质上,风险比表示当与风险比相关的预测变量增加1时,风险率会增大(或减小)多少倍。再次以上文中的“年龄”为例,我们可以看到风险比等于1.047。 这意味着,参与者的年龄每增加一岁,其风险比就会增加1.047倍。从数学角度讲,风险比即为β系数的指数形式(例如,年龄的风险比为1.047,等同于 exp(0.04589),其中0.04589是该模型中年龄的β系数)。
综合以上分析,我们可以得出该模型目前的一般结论:预计年龄较大且伴有心功能不全(射血分数低)、高血压及肾功能不全(血清肌酐水平高)的个体,其风险率将增加(从而导致生存时间缩短)。 另请注意,尽管年龄的风险比看似相对较小(例如,年龄的风险比为1.047,而高血清肌酐的风险比为2.226),但这仅反映了每年年龄增加带来的影响。 这意味着,年龄每增加一年,风险率仅增加1.047倍(即1.047),但若年龄增加十年,风险率则会增加1.58倍(即1.047的10次方)!
P 值
默认情况下,结果中不提供参数估计值的 P 值,因此本文将不作详细讨论。不过,如果您希望在分析的表格结果中包含 P 值,可以在分析对话框的“选项”选项卡中启用此选项。有关如何解读这些 P 值的更多信息,请参见此处。
模型诊断
Cox比例风险回归表格结果的下一部分提供了将指定模型与不含预测变量(协变量)的模型进行比较的信息。默认情况下,此处显示的值包括每个模型的参数数量以及赤池信息准则 (AIC) 值。其他诊断值可在分析对话框的“选项”选项卡中添加。
本节列出的 AIC 值可帮助您快速评估:分析中指定的模型是否比空模型(零模型)更能拟合数据。 AIC 值的计算方法稍显复杂,但利用这些值比较两个模型其实很简单:AIC 值越小,表明模型拟合效果越好。当不含协变量的模型 AIC 值为 1018,而分析中指定的模型 AIC 值为 960.5 时,我们可以判断指定模型更能准确描述观测数据。

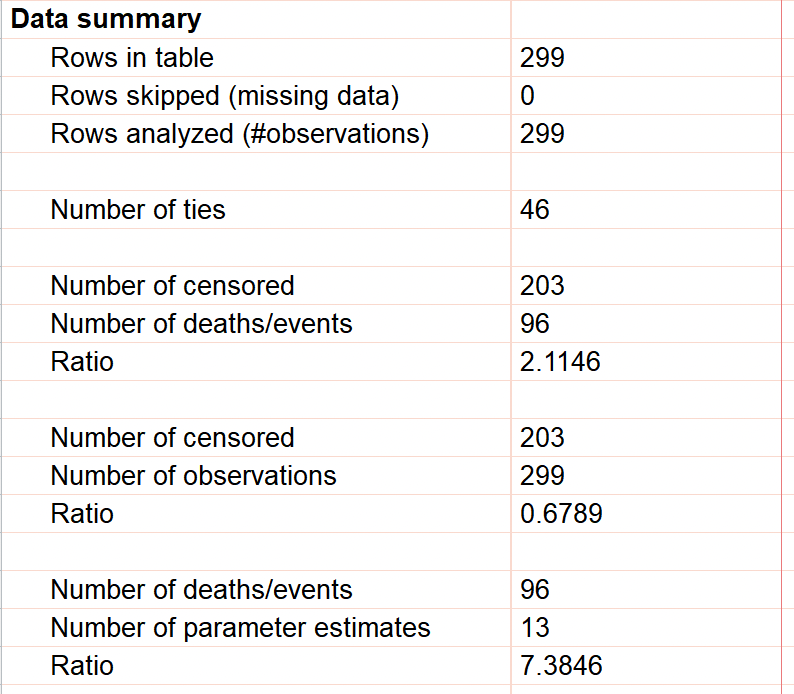
数据摘要
Cox比例风险回归表格结果页的最后一部分仅提供了输入数据的详细摘要,包括输入数据表中的行数、被跳过的行数,以及这两者之间的差值(即纳入分析的观测值数量)。 接下来,本部分报告了并列观察值的数量(即事件发生时间相同的观察值)。随后,提供了删剪观察值的数量以及记录了死亡/目标事件的观察值数量。基于这两个数值,报告了删剪观察值与事件发生的比率。 根据所研究的事件类型,该比率可能存在显著差异(当事件相对罕见时,删剪观测值与事件的比率可能较大,如本示例所示;当事件常见时,该比率可能非常小,因为大多数观测值最终都会发生该事件)。
此外,本节还会再次列出删剪观察值的数量和观测总数,并给出这两者之间的比值(即分析中使用的观测值中删剪观察值所占的比例)。最后,会再次列出记录了死亡或感兴趣事件的观测值数量,以及参数估计值的总数,并给出这两者之间的比值。通常,该参数对应的事件数比值应约为十。
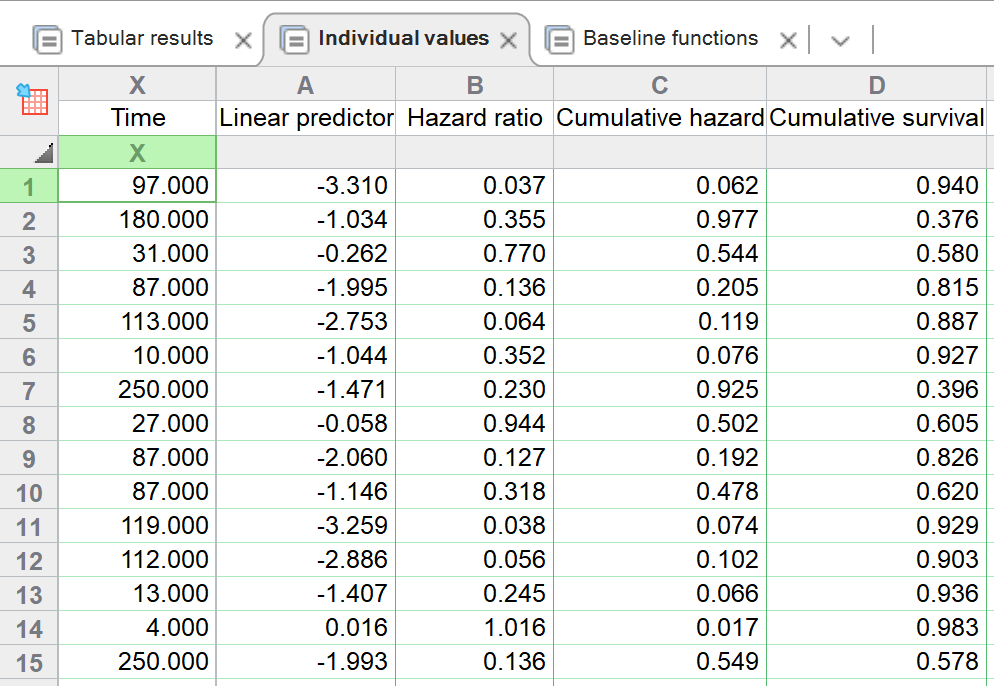
个体值
Cox比例风险回归默认会生成另外两个结果标签页。其中第一个是“个体值”标签页。顾名思义,该结果表提供了输入数据表中每个个体(行)的计算值。 该表包含每个个体的随访时间,以及线性预测因子、风险比(exp[线性预测因子]),以及根据生成的模型针对每个个体在报告的随访时间点计算出的累积风险和累积生存率。关于这些值的具体计算方法,可参阅本指南的此页面。
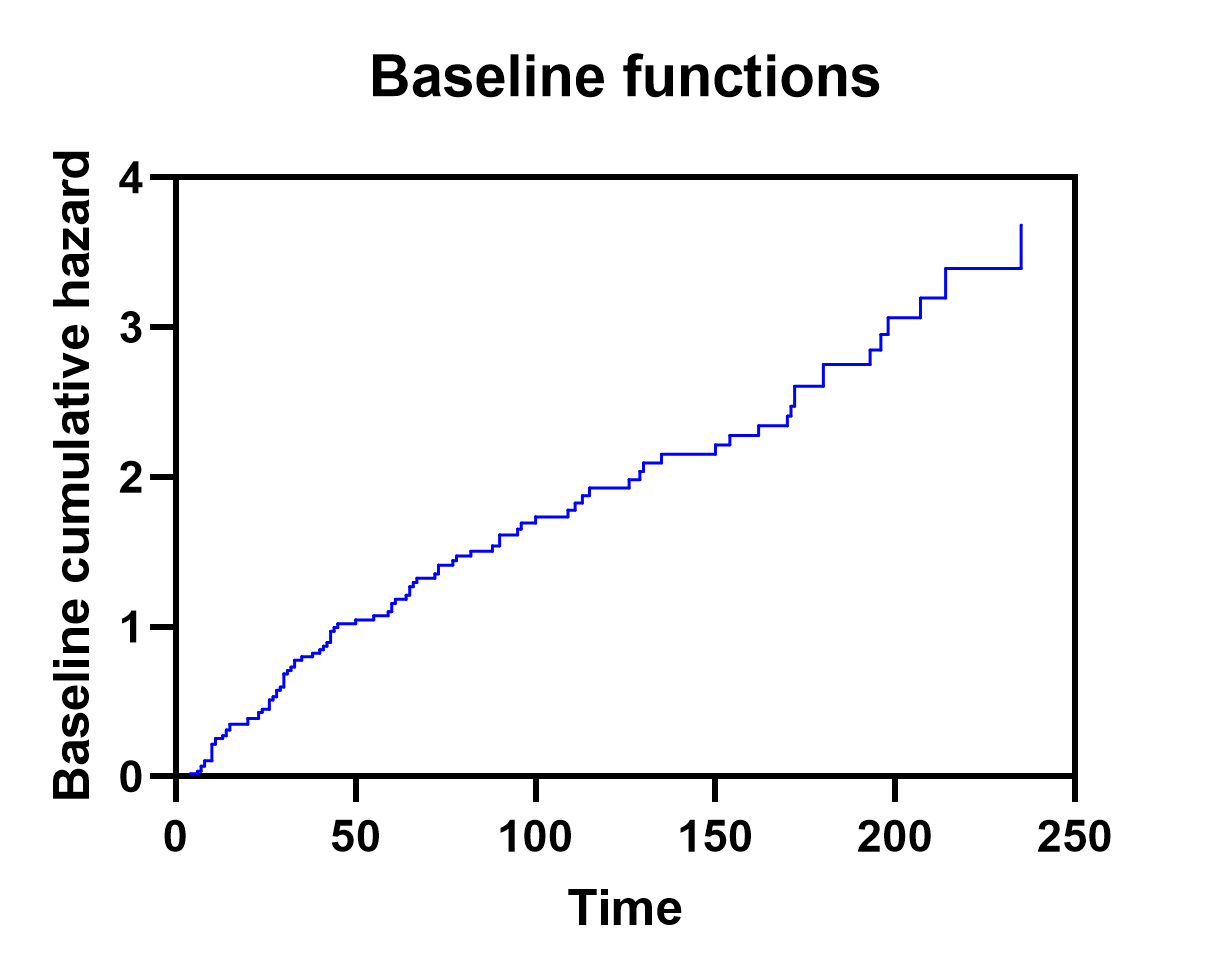
基线值
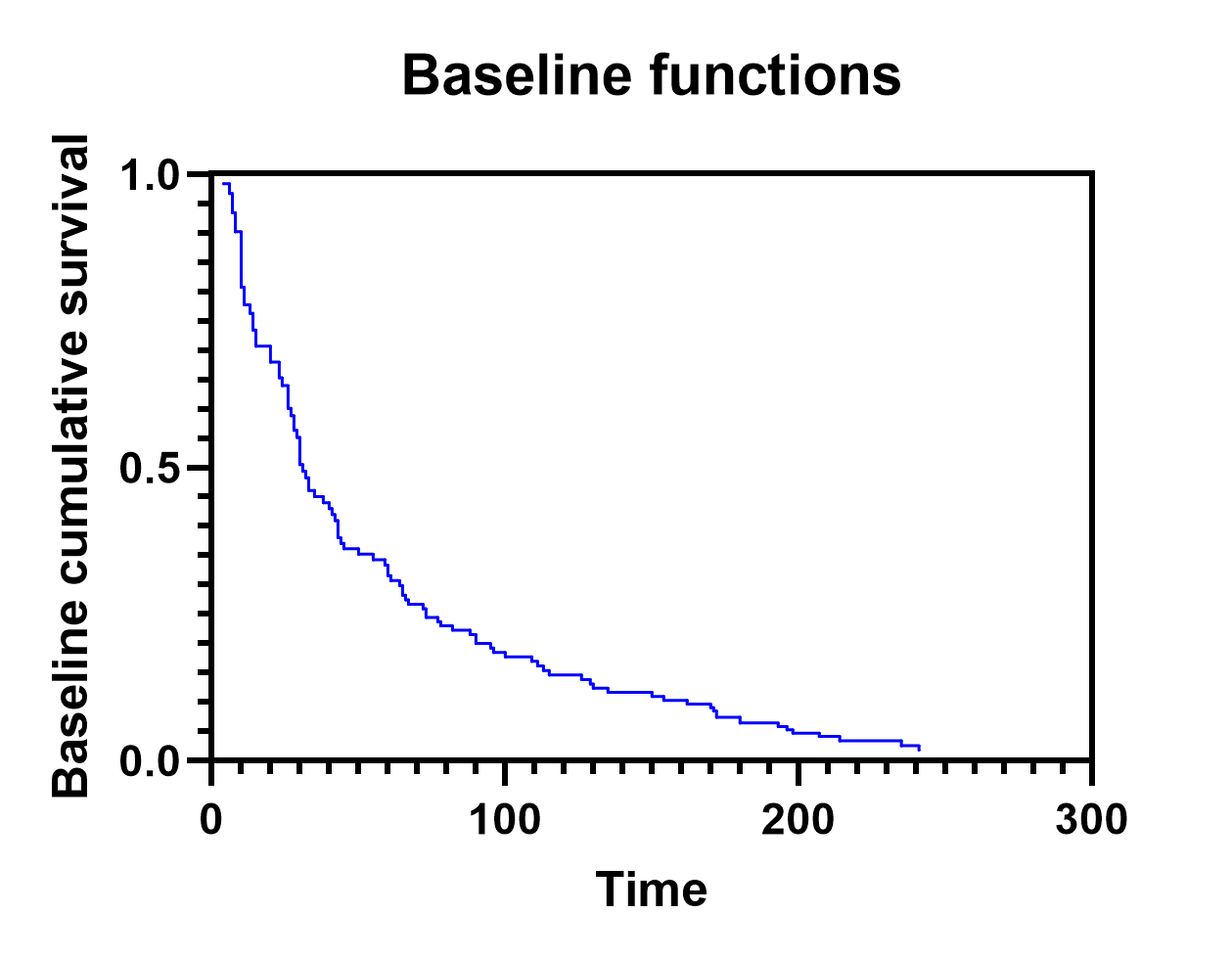
除了为输入数据表中的每个特异性观测值(行)提供估计值外,Prism 还会生成基线累积风险 (H0(t)) 和基线累积生存率 (S0(t)) 的基线值表。与“个体值”表不同,该表针对输入数据中的每个唯一时间点各包含一行,并按这些时间值升序排列。
基线累积危险度与基线累积生存率的计算方法在另一页面中详细说明,但需注意:本表格用于生成基线值图表,该图表可设置为显示基线累积危险度或基线累积生存率(下文展示了本分析的两种示例)。
重要的是,随后可利用这些基线图,结合各预测变量的参数估计值(或风险比),为特定人群构建估计的生存/风险曲线。
残差图
默认情况下,Prism将生成三种不同的残差图:
•按时间/行序绘制的标准化 Schoenfeld 残差
•偏差残差与线性预测因子/HR
•偏差残差与协变量
这些图分别可用于考察模型拟合的不同方面。
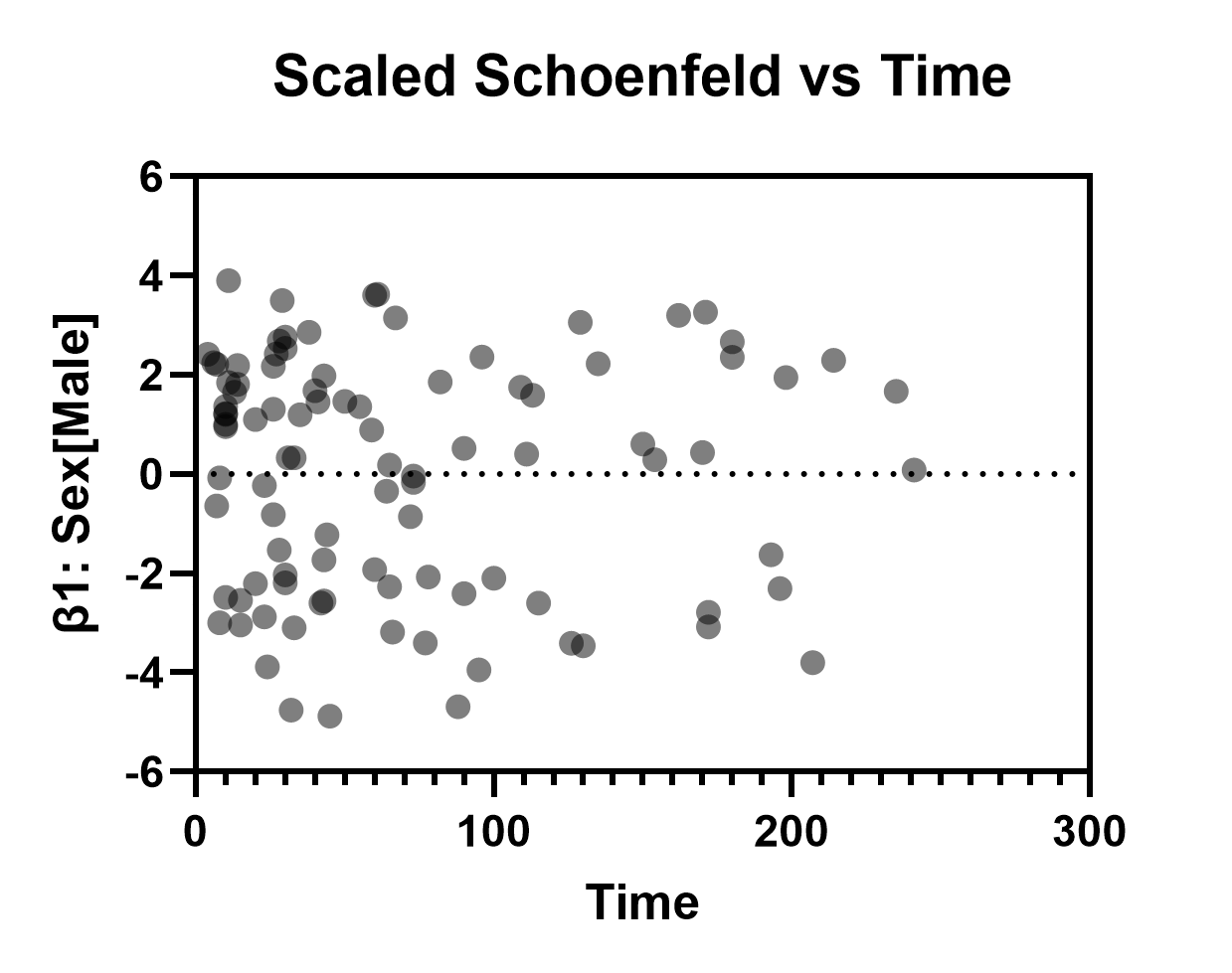
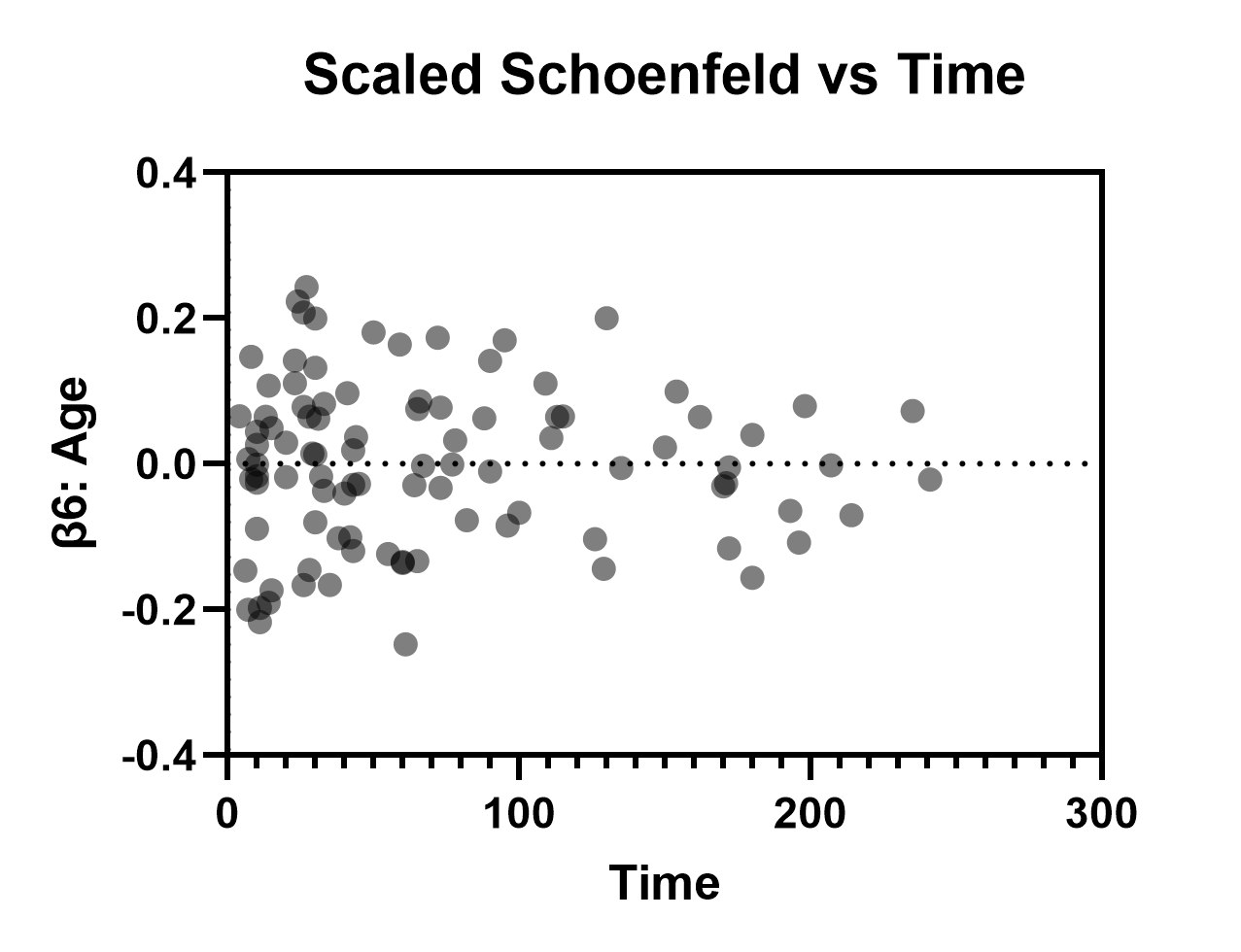
标准化 Schoenfeld 残差随时间/行序的变化
该图的主要用途是检验指定模型的比例风险假设。针对模型中包含的每个参数(在本例中为 β1 至 β13),都会生成一组标准化 Schoenfeld 残差。将这些残差绘制在 Y 轴上,以时间为 X 轴,我们预期绘制出的数据中不应存在显著趋势。 可在同一张图表中查看不同残差集(通过“设置图表格式”对话框更改Y轴绘制变量),若这些残差中出现明显趋势,则表明比例风险假设可能被违反。在本例中,该假设似乎成立(下文给出了β1:Sex[Male]和β6:Age的示例)。
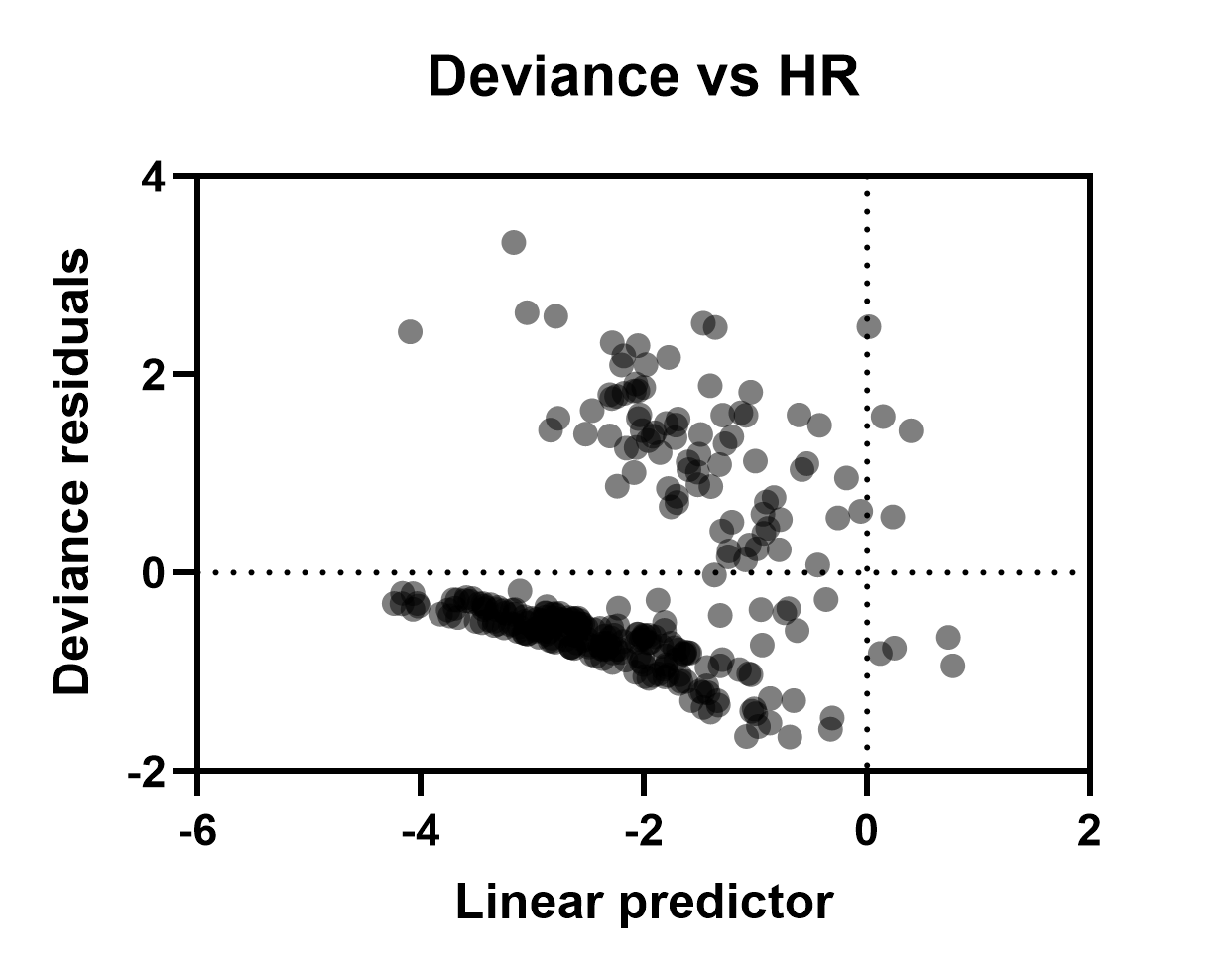
偏差残差与线性预测因子/HR的对比
该残差图可用于检查数据中是否存在潜在异常值。这些残差将围绕零点分布。极大或极小的数值代表数据中的潜在异常值。这些点表示受试者发生目标事件的时间比模型预测的要早得多(极大的正残差),或比模型预测的要晚得多(极大的负残差)。 通过“设置图表格式”对话框(双击绘图区域打开),可将每个观测值的线性预测因子或风险比(结果中“个体值”选项卡提供的数值)绘制在X轴上。这两者唯一的区别在于量纲(因为风险比是线性预测因子的指数形式)。 请注意,下图左下区域中密集的点群是由于数据集中存在大量删剪观测值所致。根据定义,删剪观测值的偏差残差必须为负值(基于计算残差所用的数学方程,此处未展示)。但从直观上讲,这确实合乎逻辑。 删剪的观测值没有观测到的事件发生时间。因此,这些观测到的事件发生时间不可能早于模型的预测时间(这是偏差残差为正的必要条件)。因此,所有删剪的观测值都必须具有负的偏差残差。
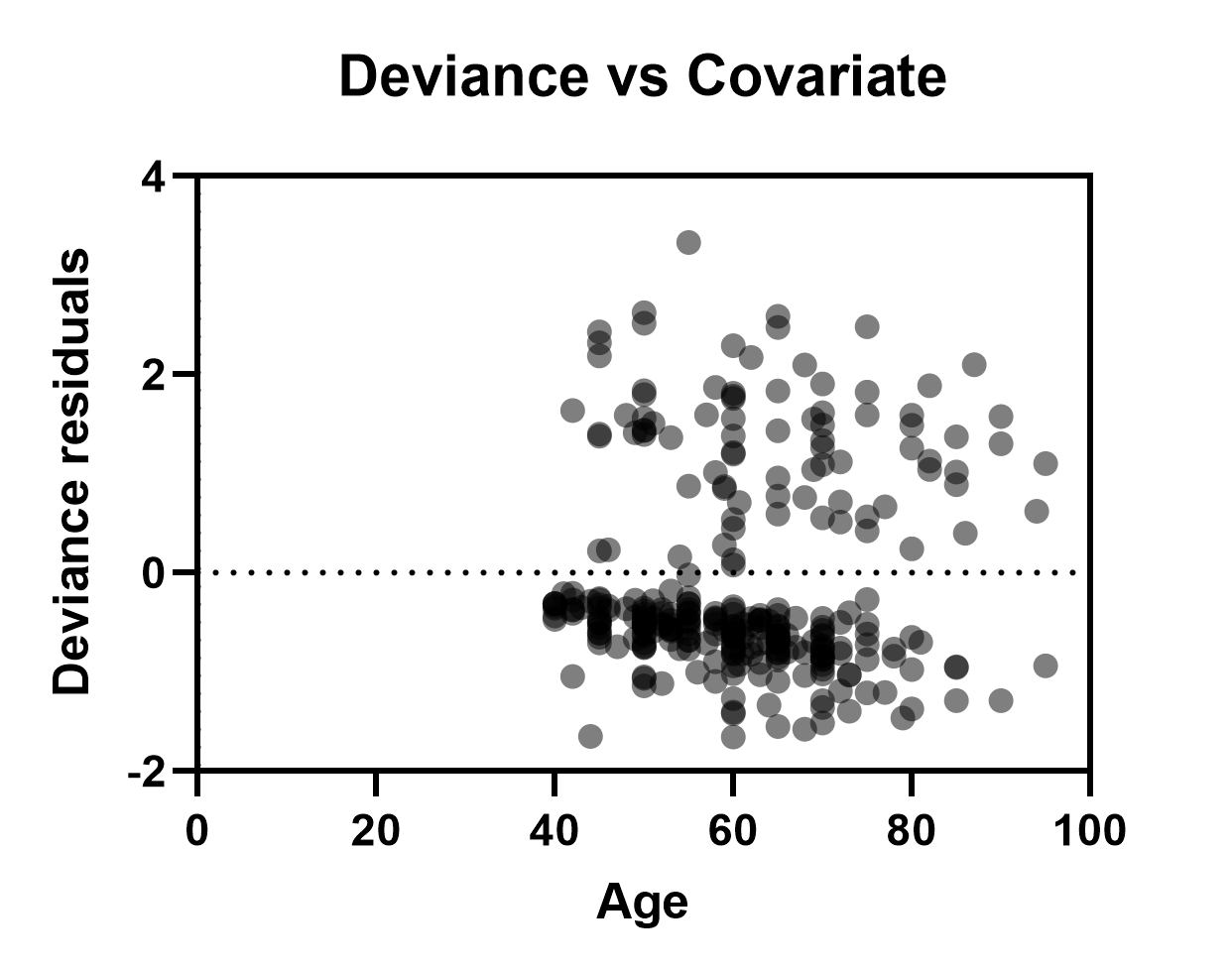
偏差残差与协变量
这些残差图用于检验各预测变量的线性假设。当将偏差残差与模型中的各预测变量作图时,预期这些残差应大致围绕零点分布。若图中出现趋势,则可能表明所选预测变量的线性假设已被违反。请注意,目前 Prism 仅能将连续预测变量(预测变量)显示在这些图的 X 轴上。 下图展示了本模型中偏差残差与年龄的关系图,未显示出明显趋势,表明该预测变量的线性假设未被违反。
估计生存曲线
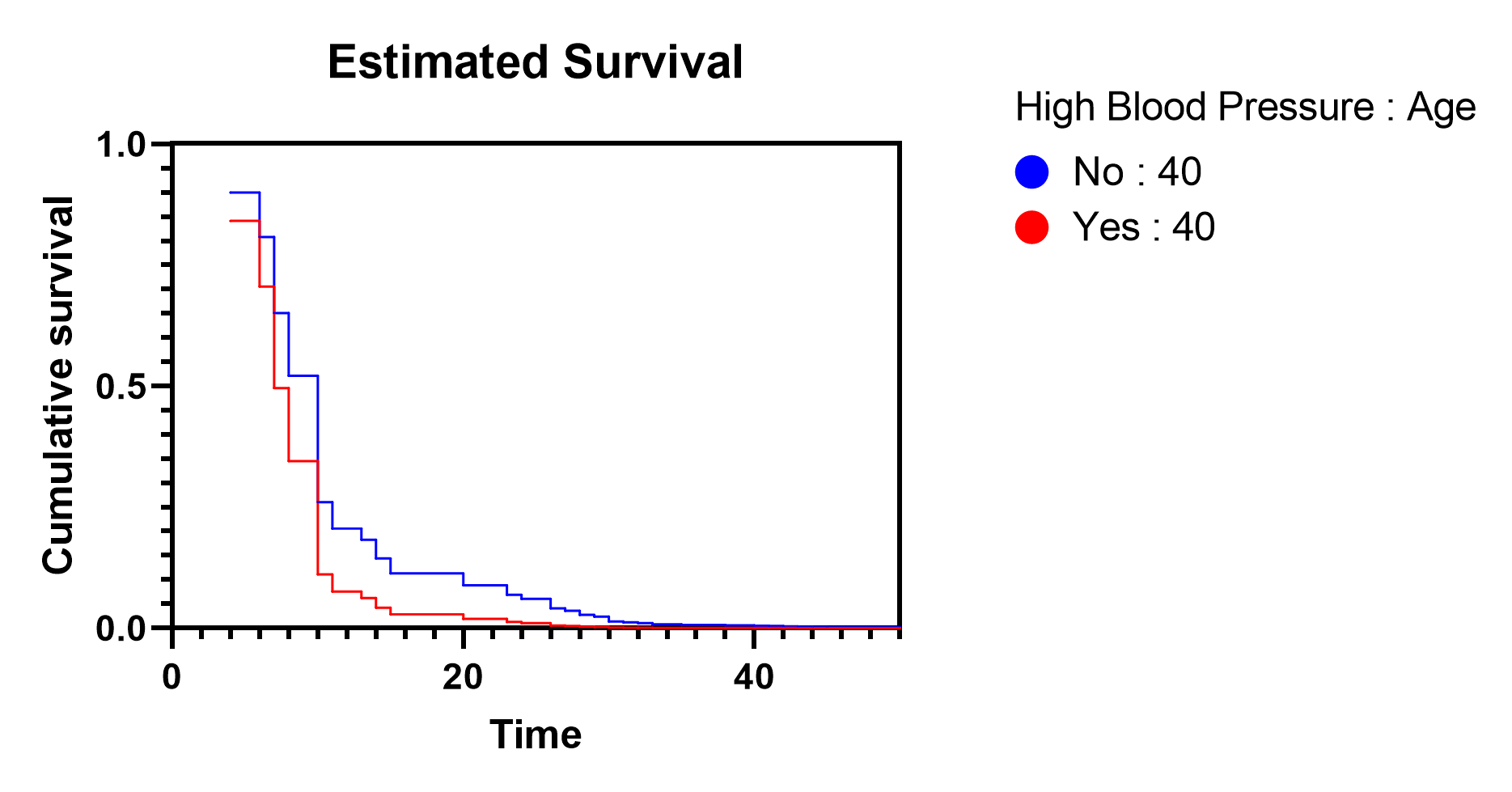
我们将要查看的分析生成的最后一张图表包含针对我们在分析参数对话框的“图表”选项卡中指定的组别的估计生存曲线。通过该选项卡中的选项,我们选择了“高血压”(同时选中“是”和“否”值)和“年龄”(取值为40)这两个变量。 Prism结合这些信息以及基线生存曲线(本页已讨论)生成了两个群体的估计生存曲线:
•患有高血压且年龄为40岁的群体
•血压低且年龄为40岁的群体
Prism生成的图表向我们展示了若干重要概念。首先,我们可以看到,高血压患者的估计生存概率低于非高血压患者。这与我们之前针对同一预测变量所看到的参数估计值(及风险比)相吻合。 正的参数估计值(β4 = 0.490)导致风险比大于1(HR=1.632),这表明与非高血压人群相比,高血压个体的风险更高(生存概率更低)。
这些估计的生存曲线所展示的另一个非常重要的概念是比例风险假设。该假设指出,每个个体的风险与某个基线风险成正比。通过不同年龄值对应的估计生存曲线,可以直观地验证这一假设。下图包含基线生存曲线以及代表不同年龄值的五条曲线。
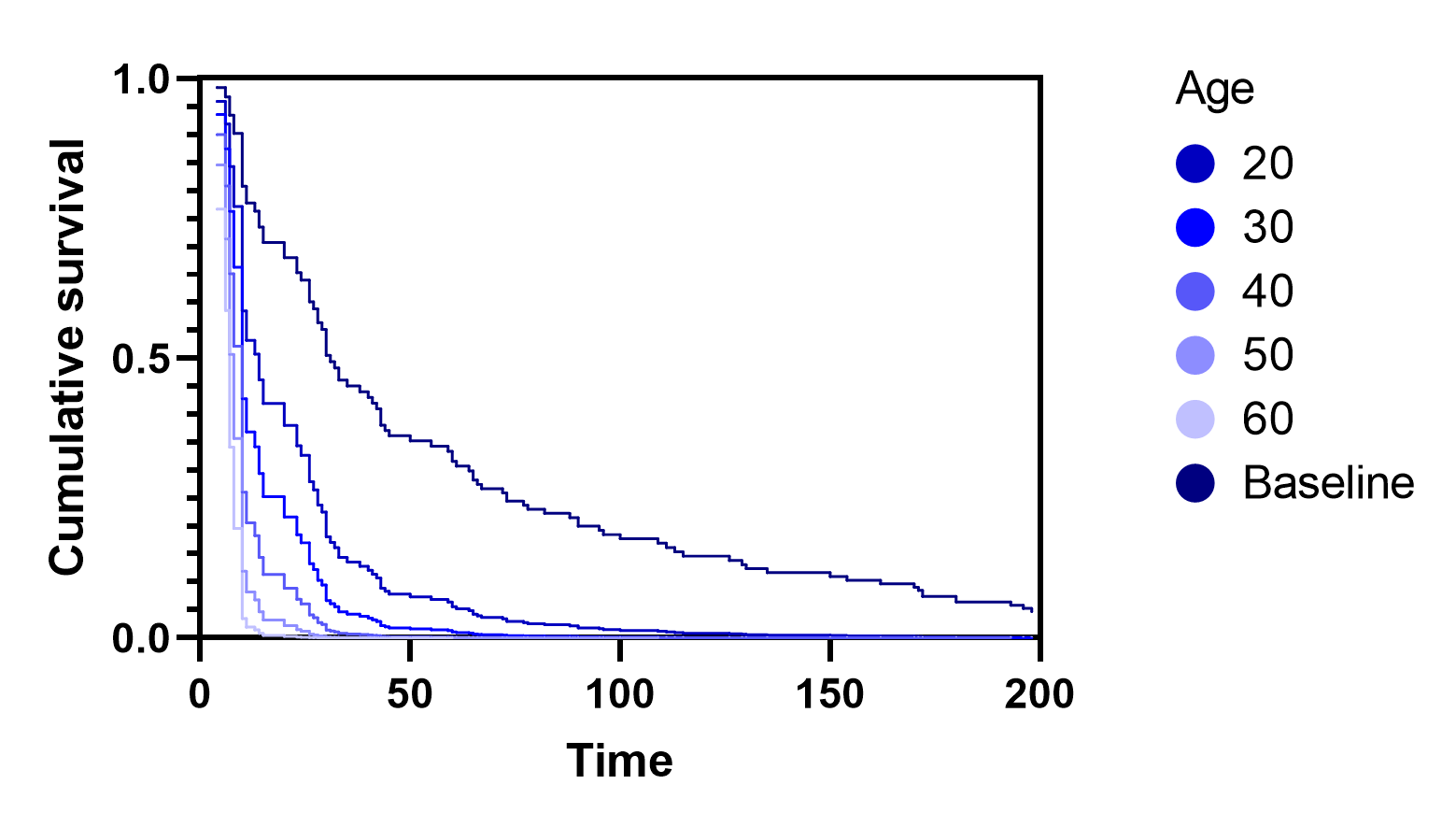
如图所示,每条生存曲线都呈现出大致相同的形状,且在任意给定时间点的具体生存概率值均与该时间点的基线生存概率成正比。