PCA的主要目标是降维。这里的“维度”简单来说就是描述数据所需的变量数量。因此,通俗地说,降维就是一种减少描述数据所需变量数量的方法。
我们为什么要降低数据的维度?
在处理大型数据集时,通常需要通过可视化检查数据来发现其中的趋势或模式。这些模式可用于对观测值进行聚类或分组,或用于理解数据中不同变量之间的关系。请看以下数据集:
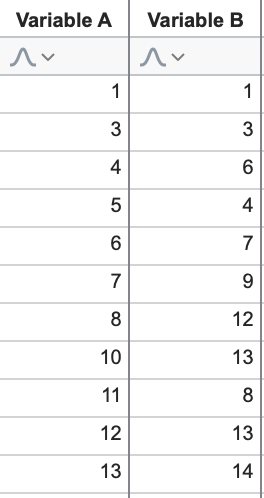
我们可以轻易看出,总体而言,随着变量 A 的增加,变量 B 也随之增加(呈正相关)。利用这些数据,我们可以快速绘制一张 XY 坐标图,直观地展示这种关系。当然,之所以能轻易看出这种关系,是因为只有两个变量!

但随着数据中变量的增加,识别数据中的潜在模式会变得更加困难。请看以下扩展的数据:
如果不绘制数据,这些关系就不再那么容易发现了。利用前三个变量,我们可以制作出这张图表,其中颜色由变量 C 的值决定:
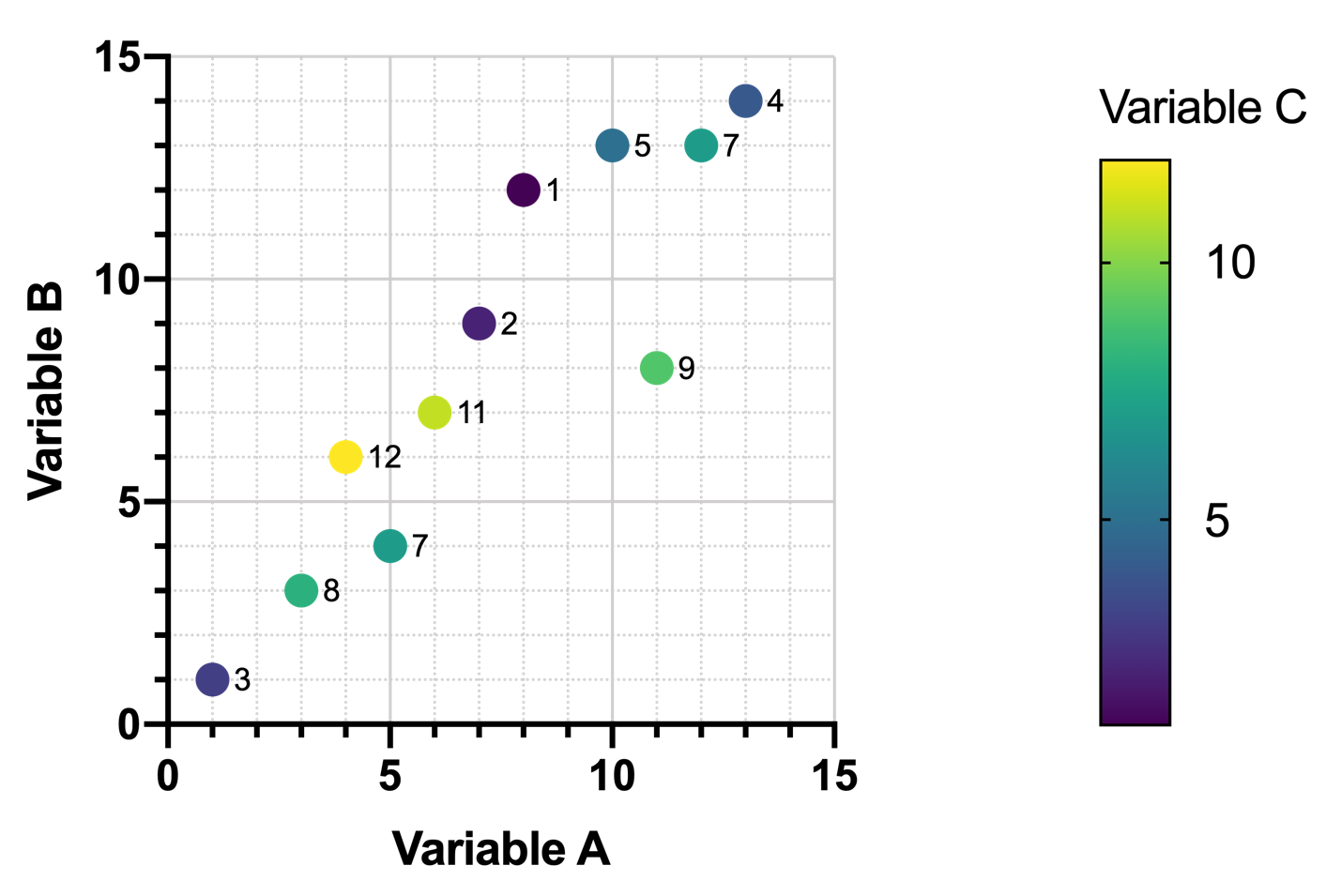
然而,即使有了这张图,变量 A 与变量 C 之间(以及变量 B 与变量 C 之间)的任何关系仍不明显。随着变量 A(或变量 B)的值增加,变量 C 的值似乎没有任何可预测的规律。
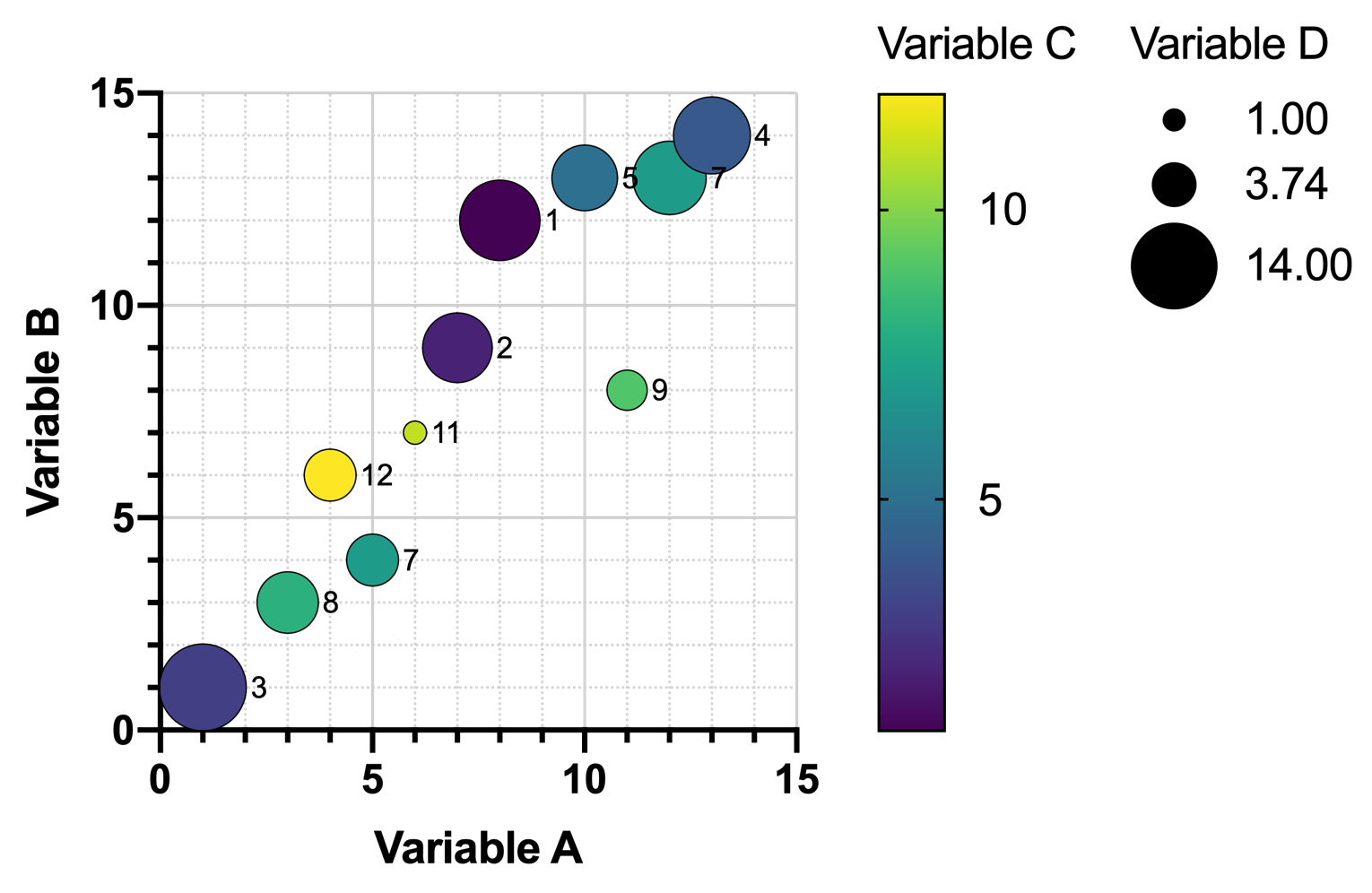
可以在该图表中添加一个额外变量,并利用其数值来决定符号大小。在下图中,符号大小与变量D的数值成正比。然而,随着数据行数的增加,此类图表会变得更加难以解读,其中的关系也绝不会跃然纸上。
如果数据集包含大量变量,几乎不可能将所有变量都呈现在单个图表上。虽然可以使用图矩阵来展示每对变量之间的关系(见下文),但这些图矩阵对于涉及多个变量的更广泛潜在关系几乎无法提供任何洞察。

一种可视化多对变量关系的替代方法,可能是使用带有额外垂直坐标轴的图表(例如带有第三个垂直坐标轴的“3D”图表,该轴代表第三个变量或第三维度)。然而,此类图表本身存在固有局限。最明显的局限在于,我们(人类)仅能感知三维空间(高度、宽度、深度)。 目前尚无任何既能直观呈现、又可同时包含超过三个坐标轴的理想方法。因此,对于包含大量独立变量的数据集,这种解决方案并不可行。
处理变量数量庞大的数据集时,还会出现其他(非视觉)问题。其中最大的问题之一是“过拟合”。此处不深入探讨细节,简而言之,当变量过多(即维度过多)时,我们为描述观测数据而构建的任何模型都会过度贴合数据,从而无法有效预测未来观测值的数值。
基于这些原因,人们开发了在不完全舍弃变量的前提下降低数据集维度数量的技术。主成分分析(PCA)便是其中之一,它高度依赖于特征提取的概念(即通过线性组合将数据投影到较少维度的空间中),相关内容将在下一节中讨论。