随研究进程动态确定样本量的吸引力
对许多人来说,在研究开始前计算样本量似乎是一件麻烦事。为什么不在收集数据的同时进行分析呢?如果结果不具有统计学显著性,那就再收集一些数据,然后重新分析;如果结果具有统计学显著性,那就停止研究,不要再浪费时间和金钱去收集更多数据。
这种方法的问题在于:若不满意结果,您会继续进行;若满意结果,则会停止。其后果是,若零假设成立,获得“显著”结果的概率将远高于5%。
通过模拟展示未预先确定样本量的风险
下图通过模拟演示了这一观点。我们从高斯分布(均值=40,标准差=15,但这些数值是任意的)中抽取值来模拟数据。两个组均采用完全相同的分布进行模拟。我们为每个组设定样本量N=5,计算非配对t检验并记录P值。随后,我们向每个组各增加一名受试者(即N=6),并重新计算非配对t检验和P值。 我们将这一过程重复进行,直至每组样本量达到N=100。随后,我们对整个模拟过程进行了三次重复。这些模拟是在两个组平均值完全相同的组之间进行的。因此,我们获得的任何“统计学显著”的结果都必然是偶然现象 - 即I类错误。
该图以P值作Y轴,样本量(每组)作X轴。图底部的绿色阴影区域表示P值小于0.05,即被视为“统计学显著”。
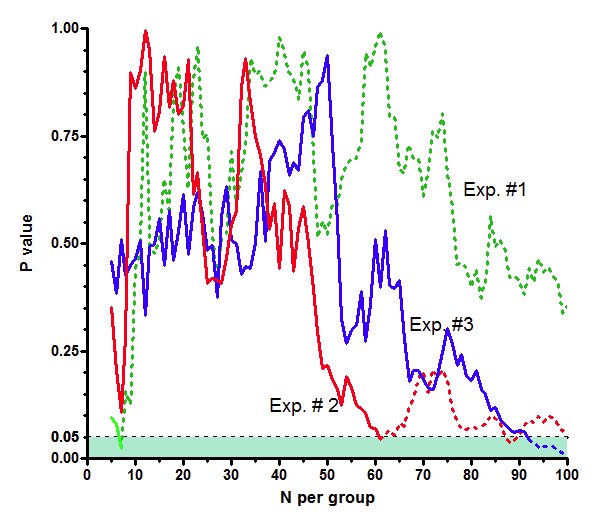
绿色曲线显示了第一组模拟实验的结果。当样本量N=7时,P值小于0.05,但在其他所有样本量下,P值均高于0.05。 红色曲线显示了第二组模拟实验的结果。当样本量N=61时,以及当N=88或89时,其P值均小于0.05。蓝色曲线代表第三组实验。当样本量N=92至N=100时,其P值均小于0.05。
若采用序贯法,我们将判定这三项实验的结果均具有“统计学显著性”。在绿色实验中,我们会在N=7时停止,因此永远不会看到其曲线中的虚线部分。红色实验会在N=61时停止,蓝色实验则在N=92时停止。在这三种情况下,我们都会判定结果具有“统计学显著性”。
由于这些模拟是针对两个总体真实均值完全相等的值生成的,因此任何“统计学显著性”的判定都属于Ⅰ类错误。如果零假设成立(两个总体的均值相等),我们预计在5%的实验中会出现此类Ⅰ类错误(若采用传统定义α=0.05,即P值小于0.05被判定为显著)。 但采用这种序贯方法,我们三次实验均产生了Ⅰ类错误。若将实验持续足够长的时间(样本量趋于无穷大),所有实验最终都会达到统计学显著性。当然,在某些情况下,即使未达到“统计学显著性”,您最终也会放弃。但这种序贯方法会在远高于5%的实验中产生“显著”结果,即使零假设为真,因此该方法是无效的。
结论
关键在于确定样本量并坚持到底。若在结果符合预期时停止,而在结果不符时继续,您将自欺欺人。如果实验在结果不具统计学显著性时继续,却在结果具有统计学显著性时停止,则错误地得出结果具有统计学显著性的概率将远高于5%。
针对序贯数据分析,存在一些特殊的统计技术:当结果模糊拟合时增加受试者数量,当结果明确时停止实验。如需了解更多,请查阅高级统计学书籍中的“序贯医学试验”相关内容。