额外平方和F检验用于比较嵌套模型
额外平方和F检验用于比较两个替代性嵌套模型的拟合优度。“嵌套”意味着一个模型是另一个模型的简单模型。让我们看看这在不同情境下意味着什么:
• 如果您要求 Prism 检验不同处理组之间的参数是否存在差异,则这些模型是嵌套的。您正在比较两种模型:一种是 Prism 为某些参数分别求得控制数据的模型,另一种是这些参数在数据集之间共享的模型。第二种情况(参数共享)比第一种情况(独立参数)更为简单(参数更少)。
• 如果您要求 Prism 检验某个参数值是否与假设值不同,那么这两个模型就是嵌套的。您正在比较两种模型的拟合效果:一种是将参数固定为假设值,另一种是让 Prism 为该参数寻找控制数据。第一种情况(固定值)比第二种情况更简单(需要拟合的参数更少)。
•如果您正在比较两个自选方程的拟合效果,且这两个模型具有相同的参数数量,则这两个模型不能被视为嵌套模型。在嵌套模型中,一个模型的参数数量少于另一个。当两个模型具有相同的参数数量时,Prism会报告无法计算F检验,因为这两个模型具有相同的自由度。 在此情况下,Prism 不会报告 P 值,而是选择绘制拟合平方和较小的模型。Prism 会显示错误信息:“模型具有相同的自由度(DF)。”
•如果您正在比较两个参数数量不同的方程拟合结果,这些模型可能属于嵌套关系,也可能不属于。Prism 不会尝试进行必要的代数运算来判断这一点。如果您选择的两个模型不属于嵌套关系,Prism 将报告额外平方和F检验的结果,但这些结果将没有实际意义。
P 值的解读
额外平方和F检验基于传统的统计假设检验。平方和F检验比较了采用复杂模型所带来的平方和(SS)改善与自由度损失之间的关系。
零假设是简单模型(参数较少的模型)是正确的。 复杂模型的改进程度通过平方和的差异来量化。仅凭偶然性就可能出现一定程度的改进,而这种偶然性带来的预期改进量由每个模型的自由度决定。平方和F检验将平方和的实际差异与预期偶然差异进行比较。结果以 F 比值表示,并据此计算出 P 值。
P值回答了以下问题:
如果零假设确实成立,在多少比例的实验(规模与您当前实验相当)中,平方和的差异会与您观察到的结果一样大,甚至更大?
如果 P 值较小,则可推断简单模型(即零假设)是错误的,并接受复杂模型。通常,P 值的阈值设定为传统的 0.05。
如果 P 值较高,则可得出结论:数据没有提供令人信服的理由来拒绝简单模型。
Prism 会标注零假设和备择假设,并报告 P 值。您可在非线性回归对话框的“比较”选项卡中设置阈值 P 值。若 P 值小于该阈值,Prism 将选择(并绘制)备择(复杂)模型。它还会报告 F 值和自由度,但这些信息仅在您需要将 Prism 的结果与其他程序或手动计算结果进行比较时才有用。
Prism 在比较模型时不报告 P 值的情况
在以下情况下,Prism 会跳过额外的平方和检验,且不报告 P 值:
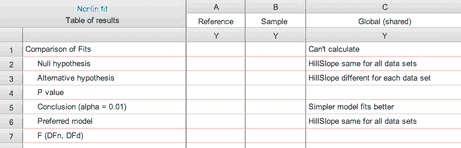
•若简单模型拟合数据的效果优于(或等同于)复杂模型。F检验的核心意义在于权衡取舍。参数更多的模型虽然拟合效果更好,但这可能仅仅是偶然因素所致。 F 检验旨在判断这种拟合度的提升(平方和的减少)是否足够显著,以“值得”牺牲自由度(即增加参数数量)。在极少数情况下,若简单模型拟合效果优于(或等同于)复杂模型(即参数较多的模型),Prism 将直接选择简单模型,且不进行 F 检验,并报告“简单模型拟合效果更好”:
• 如果任一模型的拟合结果存在歧义或被标记,Prism 将直接选择另一个模型,而不会进行任何统计检验。您可以在非线性回归的“比较”选项卡中选择关闭此标准。
•如果其中一个模型的拟合未收敛,则 Prism 会选择另一个模型,且不进行 F 检验。由于其中一个模型的拟合未收敛,比较两个模型的平方和已无实际意义。
•若其中一个模型完美拟合数据,则平方和等于零。若其中一个模型完美拟合,Prism 将直接选择该模型,而不会进行平方和F检验。
•如果两个模型的自由度相同。F检验的原理是权衡平方和的改善(拟合更好)与自由度的减少(参数更多)之间的关系。如果两个模型的自由度相同,则进行F检验毫无意义(且由于除以零在数学上是不可能的)。在这种情况下,Prism会选择拟合效果最佳的模型。