什么是均值的置信区间?
均值的置信区间(CI)告诉您,您对均值的估计有多精确。
例如,您对一个小样本(N=5)进行体重测量并计算其均值。该均值极不可能等于总体均值。可能存在的偏差大小取决于样本量和变异性。
如果样本量小且变异性大,样本均值很可能与总体均值相差甚远。如果样本量大且离散度小,样本均值则很可能非常接近总体均值。统计计算会结合样本量和变异性(标准偏差)来生成总体均值的置信区间。顾名思义,置信区间是一个数值范围。
解读均值的置信区间时,需要基于哪些假设?
要解读均值的置信区间,必须假设所有数值都是从一个总体中独立且随机抽样得到的,且该总体的数值服从高斯分布。 若接受这些假设,则95%置信区间包含真实总体均值的概率为95%。换言之,若从多个样本中生成多个95%置信区间,可以预期95%的情况下该置信区间包含真实总体均值,而在其余5%的情况下则不包含总体均值。
均值的置信区间怎么可能不包含真实均值
下图上排展示了十个数据集(N=5),这些数据集是从均值为100、标准偏差为35的高斯分布中随机抽取的。下排则显示了每个数据集的均值的95%置信区间。
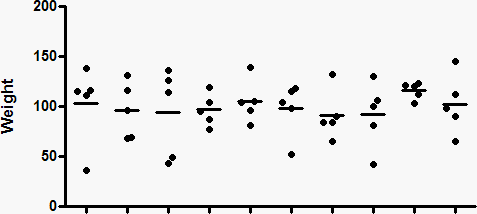
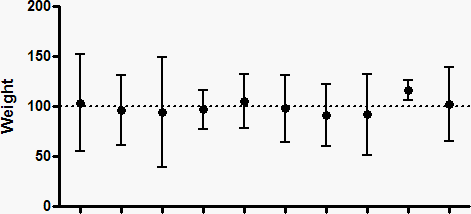
由于这些是模拟数据,我们知道真实总体均值的精确值(100),因此可以判断每个置信区间是否包含该真实总体均值。在上图从右数第二组数据集中,95%置信区间未包含真实均值100(虚线)。
在分析数据时,您并不知道总体均值,因此无法确定某个特定的置信区间是否包含真实总体均值。您唯一知道的是,该置信区间包含总体均值的概率为95%,而不包含的概率为5%。
均值的置信区间是如何计算的?
均值的置信区间以样本均值为中心,并向两个方向对称延伸。该距离等于均值的标准误乘以t分布中的一常数。该常数的值仅依赖于样本量(N),如下所示。
N |
乘数 |
2 |
12.706 |
3 |
4.303 |
5 |
2.776 |
10 |
2.262 |
25 |
2.064 |
50 |
2.010 |
100 |
1.984 |
500 |
1.965 |
N |
=TINV(0.05,N-1) |
上图所示的样本包含五个数值。因此,其中一个样本的下限置信区间计算为均值减去 2.776 倍的标准误差,上限置信区间计算为均值加上 2.776 倍的标准误差。
上表的最后一行给出了在 Excel 中计算该系数的公式。新语法为 =T.INV.2T(0.005, N-1)。
一个常见的经验法则是:95% 置信区间由均值加上或减去两个标准误差(SEM)计算得出。对于大样本而言,该法则非常准确。对于小样本而言,均值的置信区间要比该经验法则所暗示的宽得多。