事后功效分析通常没什么用
某些软件会在t检验及其他统计比较的结果中报告功效。Prism 不会这样做,本页将解释原因。
“该实验设计的功效是多少?”这一问题永远无法得到解答。该问题本身毫无意义。相反,您必须问:“该实验设计在检测特定效应量时具有多大功效?”效应量可能是两个均值之间的差异、相对风险,或是其他衡量治疗效果的指标。
应针对何种效应量计算功效?应寻找多大的差异?这些并非统计学问题,而是科学问题。只有从科学角度审视数据时,进行功效分析才有意义。计算研究设计在检测“您所关心的最小效应”时的功效是合理的;或者,计算研究在发现由先前研究确定的效应量时的功效也是合理的。
在进行统计比较计算时,某些程序会通过报告检测特定实验中实际观察到的效应量(或差异、相对风险等)的功效来补充其结果。该结果有时被称为“观察功效”,该过程有时被称为“事后功效分析”或“回顾性功效分析”。
许多(或许大多数)统计学家(我亦赞同)认为这些计算毫无用处且具有误导性。如果您的研究得出结论认为差异在统计学上不显著,那么 - 根据定义 - 其检测实际观察到的效应的功效就非常低。 通过这种计算,您无法获得任何新信息。计算研究在检测具有科学或临床价值差异时的功效或许有意义,但计算研究在检测实际观察到的差异(或效应)时的功效则毫无价值。
观察到的功效与P值直接相关
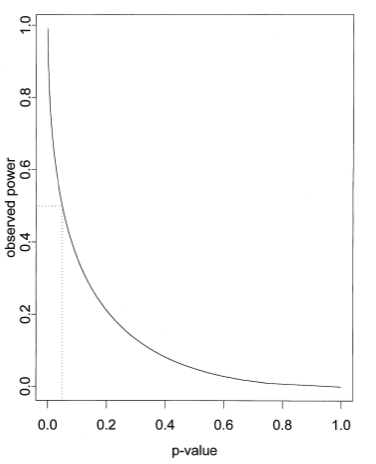
Hoenig 和 Helsey(2001)指出,观察到的功效既可以通过观察到的 P 值,也可以通过您选择的 α 值(通常为 0.05)来计算。 当 P 值为 0.05 时(假设您将统计学显著性定义为 P<0.05,因此将 α 设为 0.05),则功效必须为 50%。如果 P 值小于 0.05,则观察到的功效大于 50%。如果 P 值大于 0.05,则观察到的功效小于 50%。 观察到的功效并无新信息。下图(摘自 Helsey, 2001)展示了当 α 设为 0.05 时,非配对t检验中 P 值与观察到的功效之间的关系。
参考文献
SN Goodman 和 JA Berlin,《在设计实验时使用预测置信区间以及在解释结果时对功效的误用》,《内科学年鉴》121: 200-206, 1994.
Hoenig JM, Heisey DM, 1710, 《功效的滥用》,《美国统计学家》。2001年2月1日,55(1): 19-24. doi:10.1198/000313001300339897.
Lenth, R. V. (2001),有效样本量确定的若干实用指南,《美国统计学家》,55,187-193
M. Levine 和 M. H. H. Ensom,《事后功效分析:一个已过时的想法》,《药物治疗学》21:405-409,2001年。
Thomas, L, 《回顾性功效分析》,《保护生物学》第11卷(1997年),第1期,第276-280页