关于R2的问答
R² 量化了什么?
•R²值用于量化拟合优度。它将模型的拟合效果与一条通过所有Y值均值的水平直线的拟合效果进行比较。
•您可以将 R² 理解为模型(方程)解释了 Y 变量总方差中的比例。使用实验数据(以及合理的模型)时,您获得的结果始终会在 0.0 到 1.0 之间。
•另一种理解 R² 的方式是将其视为实际 Y 值与预测 Y 值之间相关系数的平方。
R² 的取值范围是多少?
简单的答案是,R²通常是一个介于0.0和1.0之间的分数,且没有单位。但也有特殊情况:
•当曲线通过所有数据点时,R² 等于 1.00。但如果在同一个 X 值处存在重复的 Y 值,曲线就不可能通过所有数据点,因此 R² 必须小于 1.00。
•当 R² 等于 0.0 时,最佳拟合曲线对数据的拟合效果并不比一条通过所有 Y 值平均点的水平线更好。在这种情况下,已知 X 值也无法帮助您预测 Y 值。
•当您选择了一个完全不合适的模型,或施加了荒谬的约束条件(通常是无意中造成的),最佳拟合曲线的拟合效果会比一条水平线更差。此时R²将为负值。是的,这看起来很奇怪,但R²实际上并非任何量的平方,因此这种情况是可能发生的。详情请见本页底部。
•您可能会看到关于R²可能大于1.0的论述。这种情况仅在使用无效方程时才会发生,因此该结果纯属错误。
r² 还是 R²?
按惯例,统计学家使用大写(R²)表示线性和非线性回归以及多元线性回归的结果,使用小写(r²)表示线性回归的结果,但这只是形式上的区别,实质并无差异。
为何有人建议非线性回归中不应报告 R²?
Minitab 在非线性回归中不报告 R²,因为他们认为这会造成误导。Kvalseth(1) 也对其使用提出了警示。问题包括:
•在线性和非线性回归中,R²是将最佳拟合回归线的拟合效果与一条水平线(强制斜率为0.0)进行比较。水平线是回归线的最简单情况,因此这种比较有其合理性。而在非线性回归中,由于使用了多种模型,水平线根本无法从模型中推导出来。因此,将所选模型的拟合效果与水平线的拟合效果进行比较,在数学上并不完全合理。 因此,SAS 将该值称为“伪 R²”。
•虽然人们往往倾向于使用 R² 来比较不同模型的拟合效果,但不应这样做。调整后的 R² 虽更适合此目的,但仍非理想选择。Prism 提供了两种更优的方法来比较不同模型的拟合效果。 模型选择必须权衡取舍 - 复杂模型通常拟合效果更好,但参数更多。Prism提供的两种方法都能评估这种权衡,而R²无法做到。随着模型复杂度的增加,R²值几乎总是变大,即使该模型正确的可能性较低。请勿基于R²进行模型选择。
•两个参数数量相同的模型对数据的拟合效果可能截然不同,AICc方法能告诉您其中一个模型更可能是正确的。但R²值可能仅在小数点后第三或第四位有所差异。
•较高的 R² 值表明拟合曲线与数据点非常接近。但这并不意味着在其他方面拟合优度“良好”。参数的控制数据可能毫无意义(例如负的速率常数),或者置信区间可能非常宽。拟合结果可能存在歧义。您需要查看所有结果来评估拟合效果,而不仅仅是 R² 值。
为什么 Prism 会报告非线性回归的 R² 值?
Prism 默认会计算并报告 R²。您可以在非线性回归对话框的“诊断”选项卡中关闭 R² 的报告功能,并将此设置作为未来拟合的默认选项。
许多人认为 R² 在以下方面很有用:当您进行一系列实验时,您希望确保今天的实验结果与其他实验运行结果一致。例如,如果您通常得到的 R² 值在 0.90 到 0.95 之间,但今天得到的 R² 值是 0.75,那么您应该产生怀疑,并仔细检查该特定实验中使用的方法或试剂是否出了问题。 如果新员工使用同一套系统向您提交的结果显示R²为0.99,您应该仔细核查被剔除的“异常值”有多少,以及是否存在数据造假的情况。
我认为这其实是R²值唯一有用的场景,但在此目的下它确实非常有用。
R²的计算方法 - 未加权拟合
R² 通过非线性回归确定的最佳拟合曲线与各数据点之间距离的平方和来计算。该平方和值称为 SSreg,单位为 Y 轴平方。 为了将 R² 转换为分数,需将结果除以所有 Y 值均值处水平线与各数据点距离的平方和。该值称为 SStot。如果曲线与数据拟合良好,SSres 将远小于 SStot。
下图展示了 R² 的计算过程。两个面板均显示了相同的数据和最佳拟合曲线。左侧面板还显示了一条位于所有 Y 值均值处的水平线,以及表示各点与所有 Y 值均值距离的垂直线。这些距离的平方和(SStot)等于 62735。 右侧面板显示了每个数据点与最佳拟合曲线之间的垂直距离。这些距离的平方和(SSres)等于 4165。
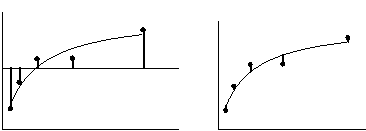
R² 通过以下公式计算:
R² = 1.0 - (SSresiduals/SStotal) = 1.0 - 4165/62735 = 0.9336
这是 Kvalseth(1) 中的方法 1。
若采用共享参数(执行全局非线性回归),则上述公式中的SSresiduals即Prism在“全局结果”列中针对所拟合的共享参数模型报告的平方和,而SSTotal则是每个Y值(来自各数据集)相对于所有Y值均值(来自所有数据集)的平方和。
R²的计算方法 - 加权拟合
目前似乎尚无计算加权非线性拟合 R² 的标准方法。Prism(自 6.00 版起)的计算方法如下所述。但请注意,Prism 的早期版本对加权拟合的 R² 计算方式有所不同。
1.使用相对权重(1/Y²)、泊松(1/Y)或通用(1/XK)加权方法拟合模型,以计算加权平方和(wSSmodel)。这是模型残差的加权平方和。
2.请记住每个数据点所对应的权重。
3.使用与步骤 1 中相同的权重,将数据拟合到水平线模型(Y=均值 + 0*X)。这是水平线残差的加权平方和(wSShorizontal)。
加权 R² 为:
1.0 - (wSSmodel/wSShorizontal)
请注意,权重仅在拟合模型时计算。Prism不会为水平直线的拟合单独计算权重,而是直接使用与拟合模型时完全相同的权重。这确保了两次拟合中权重的总和完全一致。
更多细节请参见 Willett 和 Singer (2) 中的方程 4。
R² 为何会为负值?
平方值怎么会是负数?其实,R² 并不是任何量的平方。它是通过两个值的差来计算的。如果 SSres 大于 SStot,R² 就会为负(参见上文公式)。
这怎么可能发生?SSres 是数据点到最佳拟合曲线(或直线)的垂直距离平方和。SStot 是数据点到以 Y 均值绘制的水平线的垂直距离平方和。当最佳拟合线或曲线对数据的拟合效果甚至比水平线更差时,SSres 就会超过 SStot。
当最佳拟合直线或曲线对数据的拟合效果极差时,R² 值将变为负数。这种情况仅可能发生在:您拟合了一个选择不当的模型(可能是误操作),或者对模型施加了毫无意义的约束条件(例如本意输入负数却误输入了正数)。 例如,若将剂量反应曲线的Hill斜率约束为大于 1.0,但曲线实际呈下降趋势(即Hill斜率为负值),则可能导致 R² 值为负,且参数值毫无意义。
下面是一个简单的示例。 蓝色曲线是受限于当 X=0 时与 Y 轴在 Y=150 处具有截距的直线拟合结果。SSres 是红色数据点到这条蓝色曲线的距离平方和。SStot 是红色数据点到绿色水平线的距离平方和。由于 Sres 远大于 SStot,因此(蓝色曲线的)R² 值为负。
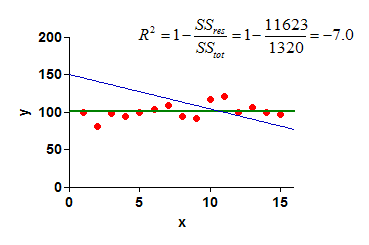
若 R² 为负值,请检查所选模型是否合适,并确认约束条件设置正确。
1.Kvalseth, T.O. (1985) 关于 R² 的警示性说明。《美国统计学家》,39,279-285。
2.Willett, J.B. 和 Singer, J.D. (1988). 关于 R² 的另一项警示:其在加权最小二乘回归分析中的应用。《美国统计学家》42: 236.