为什么不应使用R²来比较模型
R² 量化了模型对数据的拟合程度,因此看起来似乎是比较模型的一种简单方法。这听起来确实很简单 - 选择 R² 值更大的模型。这种方法的问题在于,增加参数不会受到任何惩罚。 因此,参数更多的模型会通过更复杂的曲折调整来贴近数据点,因而其R²值几乎总是更高。若将R²作为选择最佳模型的标准,结果几乎总是会选中参数最多的那个模型。
调整后的R²考虑了拟合参数的数量
调整后的R²值总是低于原始R²(除非您只拟合一个参数)。下面的公式说明了原因。
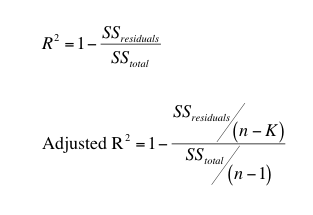
上述方程展示了调整后R²的计算方法。 回归直线或曲线残差的平方和具有 n-K 个自由度,其中 n 是数据点数,K 是回归拟合的参数数。总平方和是所有 Y 值均值处水平线与数据点距离平方之和。由于它只有一个参数(均值),因此自由度等于 n-1。
当 K=1 时,调整后 R² 与普通 R² 完全相同。当 K>1 时,调整后 R² 小于普通 R²。
利用调整后的R²及简便方法比较模型
比较模型的一种快速简便方法似乎是选择调整后R²值较小的模型。建议在“诊断”选项卡中报告该值。
使用调整后的R²比较模型是多元线性回归中比较拟合模型的标准方法。但出于充分的理由,这并非非线性回归的标准做法。Speis和Neumeyer(1) 通过模拟实验表明,使用调整后的R²来在竞争模型中进行选择是一种非常糟糕的方法。 我们建议您改用额外平方和F检验或比较 AICc。如果您确实要通过比较调整后的 R² 来比较模型,请确保所有拟合均使用完全相同且加权方式一致的数据。但即使如此,也请注意:根据 AICc 评估,拟合效果差异显著的模型,其 R² 值可能仅在小数点后第三至第五位数字上有所不同(1)。
线性回归中的调整后R²
Prism 在线性回归中不报告调整后的 R²,但您可以通过非线性回归拟合直线。
如果 X 和 Y 之间完全不存在线性关系,则最佳拟合斜率预计为 0.0。如果您分析了许多随机选取的样本,一半样本的斜率将为正,另一半样本的斜率将为负。 但在所有这些情况下,R² 值均为正(或零)。R² 值绝不会为负(除非您限制斜率或截距,迫使拟合效果比水平线更差)。相比之下,调整后的 R² 值可以为负。如果您分析了大量随机选取的样本,预计一半样本的调整后 R² 值为正,另一半为负。
以下是一种理解二者区别的简明方法。R² 量化了您正在分析的数据样本中的线性关系。即使潜在数据集中不存在线性关系,该样本中也几乎肯定存在某种关系。调整后的 R² 值小于 R²,它是您对潜在总体中关系程度的最佳估计。
1. Spiess, A.-N. & Neumeyer, N. 《R²作为药理学和生物化学研究中非线性模型不恰当指标的评估:一种蒙特卡洛方法》。BMC Pharmacol 10, 6–6 (2010).