当拟合的模型不正确时,剔除异常值会产生误导
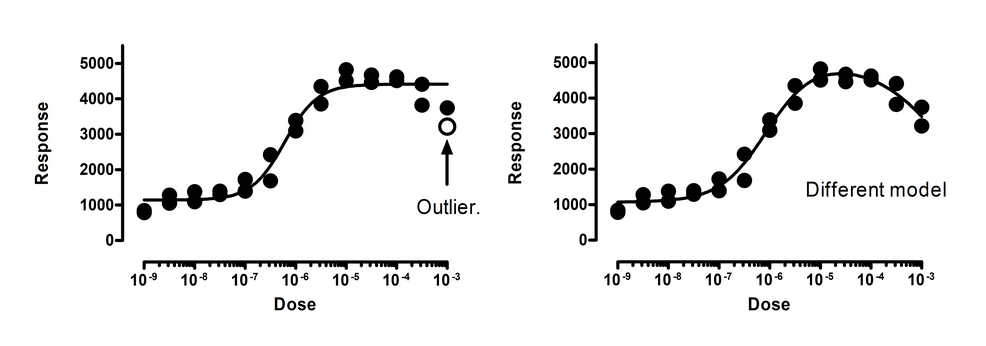
上图左侧展示了数据拟合于剂量反应曲线的结果。在此图中,其中一个数据点是一个显著的异常值。但这种解读的前提是您选择了正确的模型。右侧展示了数据拟合于另一种钟形剂量反应模型的结果,在此模型中,高剂量引发的反应比中等剂量更小。数据与该模型拟合得非常好,未检测到(甚至未怀疑)任何异常值。
本示例说明,只有在确信拟合的是正确模型时,剔除异常值才是恰当的。
当数据点不独立时,剔除异常值会产生误导
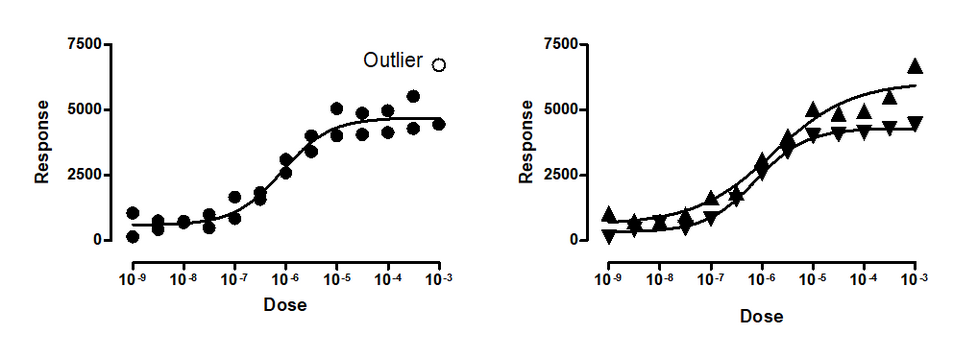
上图左侧面板显示了拟合于剂量-反应模型的数据,其中一个数据点(位于右上角)被识别为异常值。 右侧图表显示,这些数据实际上来自两个不同的实验。第二个实验的低平台期和高平台期(用向上三角形表示)均高于第一个实验(用向下三角形表示)。由于这是两个不同的实验,左侧图表中的分析违反了独立性假设。当我们分别拟合每个实验运行时,未检测到异常值。
如果选择的加权因子不正确,剔除异常值会产生误导
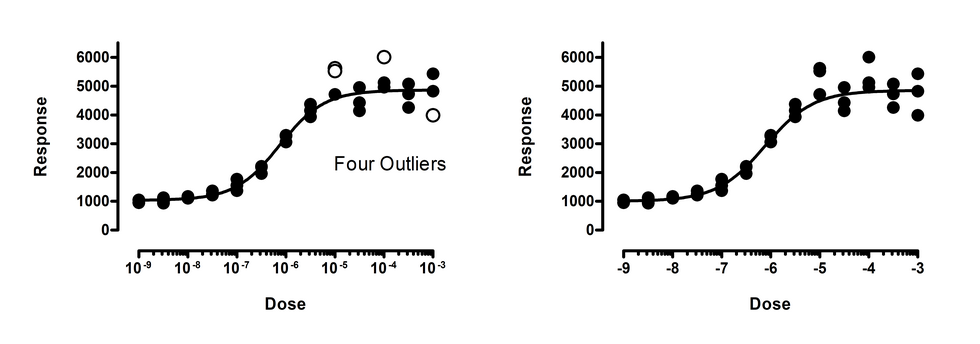
上图左侧面板展示了拟合于剂量反应模型的数据。识别出四个异常值(其中两个几乎重合)。但请注意,响应值(Y值)较大的数据点,平均而言也离曲线更远。这使得最小二乘回归不适用。为了考虑残差的标准差与曲线高度成正比这一事实,我们需要使用加权回归。 右侧图表展示了同一组数据拟合至相同剂量反应模型的结果,但采用相对权重法,将“点与剂量反应曲线的平方和除以曲线高度”的值最小化。此时未识别出任何异常值。使用错误的权重方法会产生虚假的异常值。