如果只是查阅“特征值”或“特征向量”的严格定义,恐怕很难得到关于这些值所代表含义的合理解释,除非您深入研究用于计算它们的必要矩阵代数。相反,让我们回到数据的可视化表示以及为其识别出的第一个主成分:
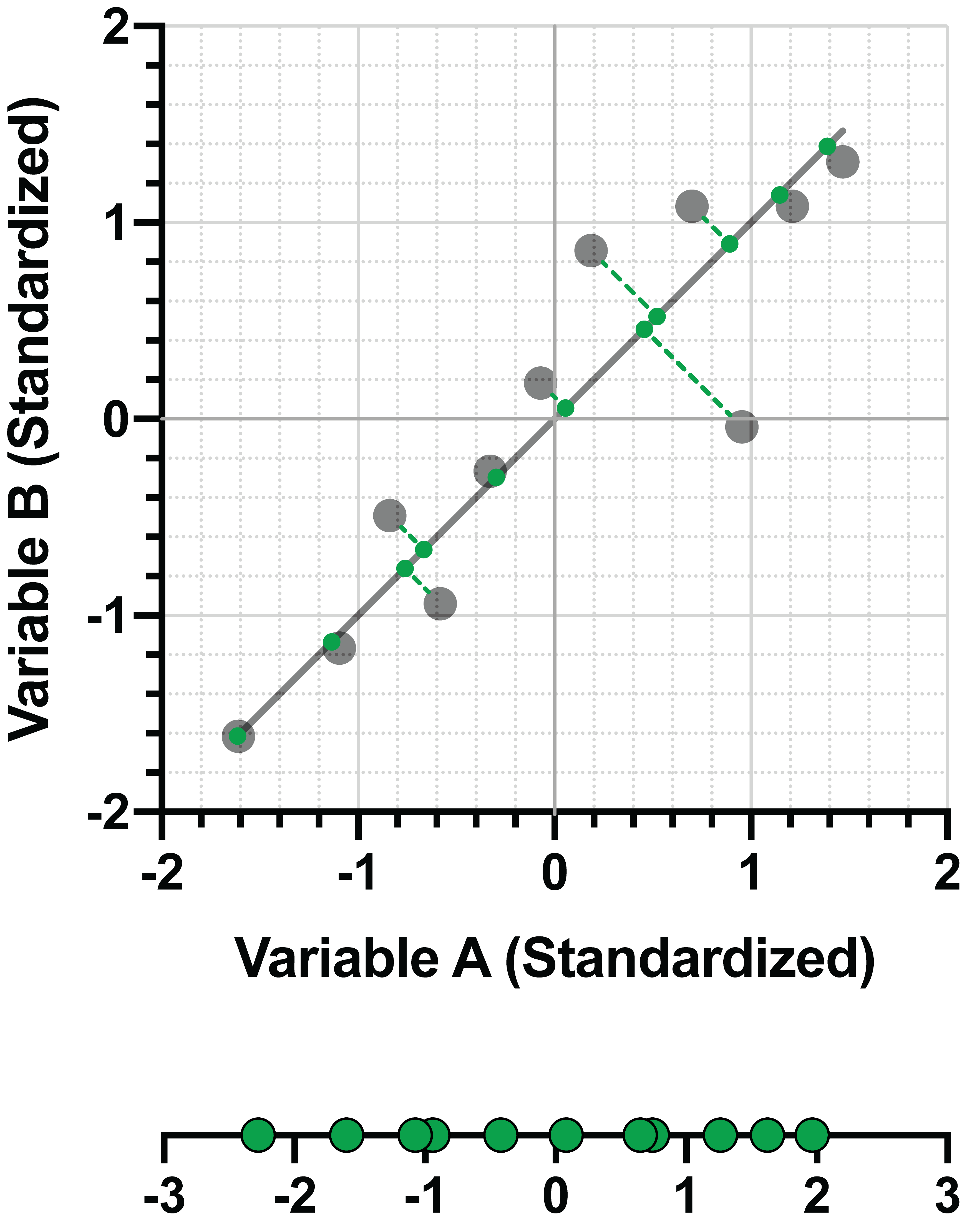
该主成分被表示为以下线性组合:
PC1 = 0.707*(变量 A) + 0.707*(变量 B)
系数(变量A为0.707,变量B为0.707)共同构成了PC1的特征向量。简而言之,这些数值代表了第一个主成分的“方向”,就像斜率指示回归线的方向一样。 从上图坐标 (0,0) 开始,可以看出该直线的“方向”是沿变量 A 轴向右移动 0.707,沿变量 B 轴向上移动 0.707。连接这两个点的直线即为 PC1。
进阶说明:特征向量(如同所有向量)既具有方向,也具有大小(即长度)。二维空间中向量的方向可通过两个值来定义 - 向量在第一维方向上的分量,以及向量在第二维方向上的分量。维度越多,描述向量所需的值就越多。在PCA中,单个特征向量对于每个原始变量都对应一个值。
为什么特征向量最终会得到这些奇怪的小数值,而不是像 1 和 1 这样更简单的数值?这归结于毕达哥拉斯定理。在本示例中,我们已经看到 PC1 是那条通过坐标 (0,0) 和特征向量给出的坐标 (0.707, 0.707) 的直线。 如果我们要确定连接这两个点的线段长度(也称为向量的大小),我们会发现它等于 1!
d = √[(0.707-0)² + (0.707-0)²] = 1
*注意,数值 0.707 是四舍五入后的结果,因此上述公式的计算结果会略有偏差
事实上,这是所有主成分(PC)特征向量都具备的性质。特征向量的长度始终为1,这可以通过计算特征向量各分量的平方和来验证。让我们以上述相同数据为例,观察PC2的情况:
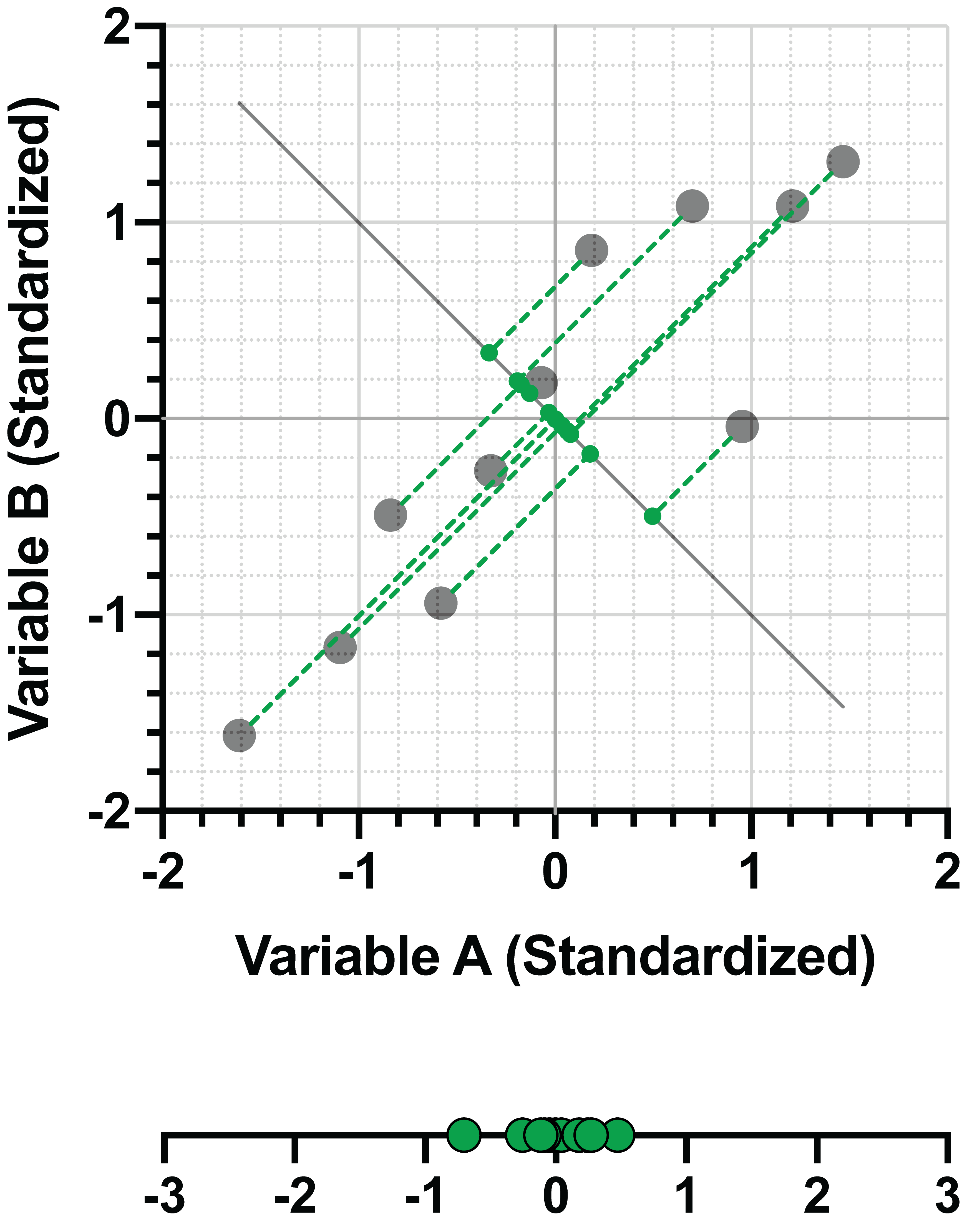
PC2 = -0.707*(变量 A) + 0.707*(变量 B)
同样地,
d = √[(-0.707)² + (0.707)²] = 1
因此,特征向量指明了每个主成分的方向。那么特征值又代表什么呢?事实证明,这些数值代表了主成分所解释的方差量。 对于针对单一数据集确定的主成分集,特征值较大的主成分所解释的变异性会比特征值较小的主成分更多。由此,特征值可被视为与特征向量方向相伴的主成分长度。请注意,在某些情况下,会使用因子载荷来描述原始变量与主成分之间的这种关系。本节将进一步探讨因子载荷的含义及其与特征向量的关系。
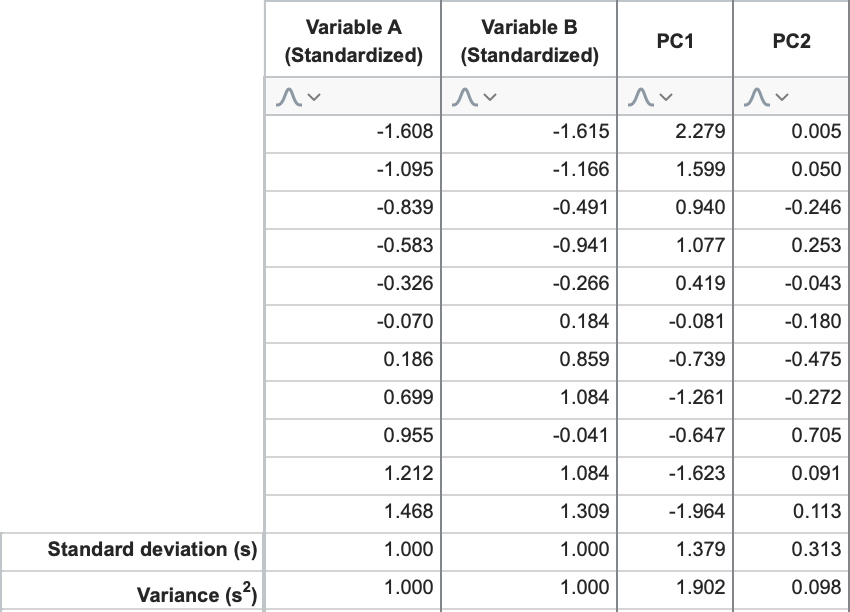
继续本示例,PC1和PC2的特征值分别为1.902和0.098。这印证了我们之前所说的:第一个主成分解释了最大的方差,而随后的每个成分解释的总方差越来越少。要直接计算这些值,请考虑我们使用线性组合和标准化数据为PC1和PC2计算的“得分”。
若计算“PC1 得分”和“PC2 得分”列的标准偏差,并将其平方(方差 = [标准偏差]²),结果便是……您猜对了:分别是 1.902 和 0.098。
特征值之和与原始变量数量
在继续进行成分选择之前,还有关于特征值的另一个有趣方面值得讨论。即 - 如果您使用标准化数据进行分析 - 所有主成分(PCs)的特征值之和将等于原始变量的总数。为什么?
请记住,数据标准化后,每个变量的方差都等于 1。由此推论,数据集中的总方差量等于变量的总数。 每个主成分“解释”的方差量等于其特征值,但不会改变数据中总体方差的总量。由于将数据投影到新主成分上并未消除任何方差,因此所有主成分解释的方差之和必须等于总方差。因此,特征值之和 = 解释方差之和 = 总方差 = 原始变量总数。
这一事实在选择主成分子集以实现降维时非常有用。