在前一节中,我们看到,第一主成分(PC)是通过最大化投影到该成分上的数据方差来定义的。然而,由于原始数据中包含多个变量(维度),可能需要添加额外的成分,以保留第一主成分未能充分解释的额外信息(方差)。
从数据中可以提取多少个主成分?
一般而言,数据集可通过其包含的变量(列)数和观测值(行)数来描述。变量数通常用 p(代表“预测变量”)表示,观测值数通常用 n 表示。
对于一个数据集,可确定的主成分总数等于 p 或 n 中的较小值。但需注意以下两点:
•在许多数据集中,p 会大于 n(即变量数多于观测数)。这种“宽”数据对 PCA 来说不是问题,但在其他分析技术(如多元线性回归或多元逻辑回归)中可能会引发问题
•通常很少需要保留所有可能的主成分(下一节将对此进行详细讨论)
为简化起见,我们将假设处理的数据集属于变量数多于观测值的情况(p > n)。不过,在定义主成分时,其过程是相同的。确定第一个主成分(即使投影数据到该直线上的方差最大化的变量线性组合)后,下一个主成分的定义与第一个完全相同,但需满足一个限制条件:它必须与先前定义的主成分正交。
在二维空间中这一点很容易理解:两个主成分必须相互垂直。让我们再次回到变量A和B的标准化数据。
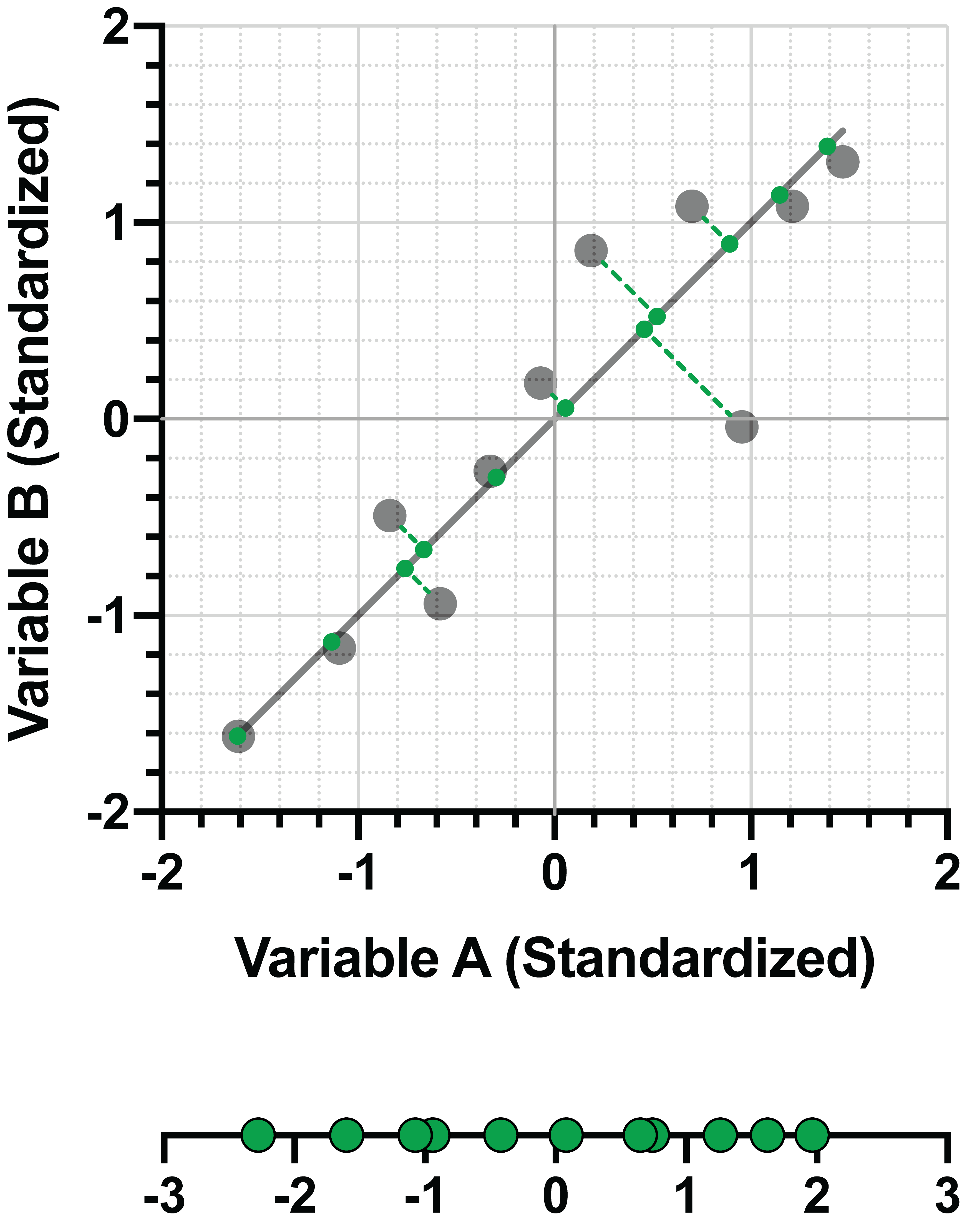
我们知道该数据的图形如下所示,且第一个主成分可通过最大化数据投影到该直线上的方差来定义(上一节已详细讨论):

由于我们受限于二维空间,因此只有一条直线(绿色)能够与这条第一个主成分线垂直:

在前面的章节中,我们已经展示了这个第二主成分(PC2)在投影数据中捕获的方差比第一主成分(PC1)要少:
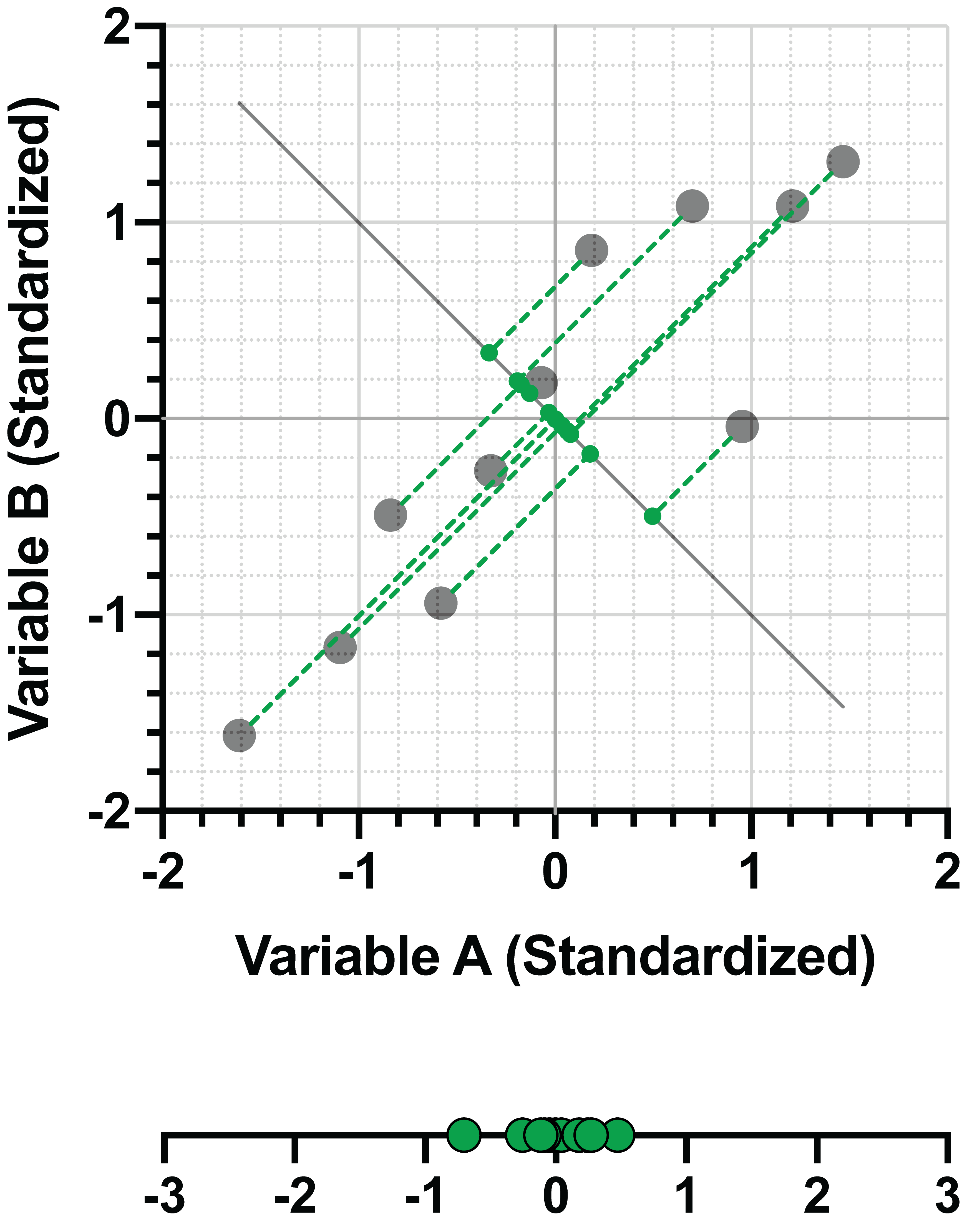
然而,在与第一主成分正交的约束条件下,该主成分能最大化数据的变异性。与之前一样,我们可以将该主成分表示为标准化变量的线性组合。以下是 PC1 和 PC2 的线性组合:
PC1 = 0.707*(变量 A) + 0.707*(变量 B)
PC2 = -0.707*(变量 A) + 0.707*(变量 B)
进阶说明:该线性组合的系数可以表示为矩阵形式,在此形式下被称为“特征向量”。该矩阵通常作为PCA结果的一部分呈现
利用这一线性组合,我们可以将 PC2 的“得分”添加到数据表中:
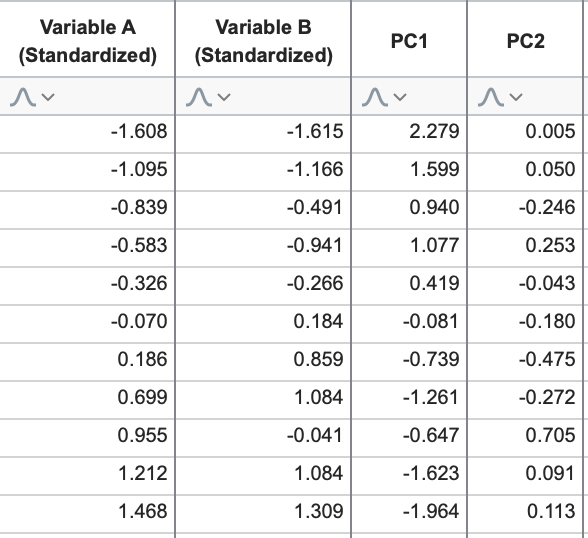
如果原始数据包含更多变量,只需重复此过程:
•寻找一条能使投影到该直线上的数据方差最大化的直线。这就是第一个主成分(PC)
•寻找一条既能最大化数据在该线上投影的方差,又与之前所有已识别的主成分正交的直线。这就是下一个主成分
在二维空间中可视化这一过程相当直观。理解三维空间中三条直线如何以90°角相交也是可行的(考虑三维图形的X、Y和Z轴;这些轴彼此均呈直角相交)。 然而,随着原始数据维度的增加,可能的主成分数量也会随之增加,可视化这一过程的难度便会急剧上升(试想在六维空间中,一条直线与另外五条直线相交,且所有交点都必须呈90°角……)。
幸运的是,识别数据集中后续所有主成分的过程与识别前两个并无二致。最终,您会得到一个按优先级排序的主成分列表,其中第一个主成分“解释”了数据中最大的方差,第二个主成分“解释”了次大的方差,以此类推。 下一节将探讨如何呈现这种“解释方差”的数值,以及如何利用这些信息做出决策,从而实现PCA的目标:降维。