本指南将带您逐步了解如何使用 Prism 进行多元逻辑回归。逻辑回归功能是在 Prism 8.3.0 版本中新增的
数据
首先,我们需要在“欢迎”对话框中创建一个新的“多变量”数据表
在多变量数据表的教程数据集列表中,选择“多变量逻辑回归”示例数据
该示例数据共有五个列:“Survived?”、“Age (in years)”、“Male?”、“1st Class?” 和 “2nd Class?”。
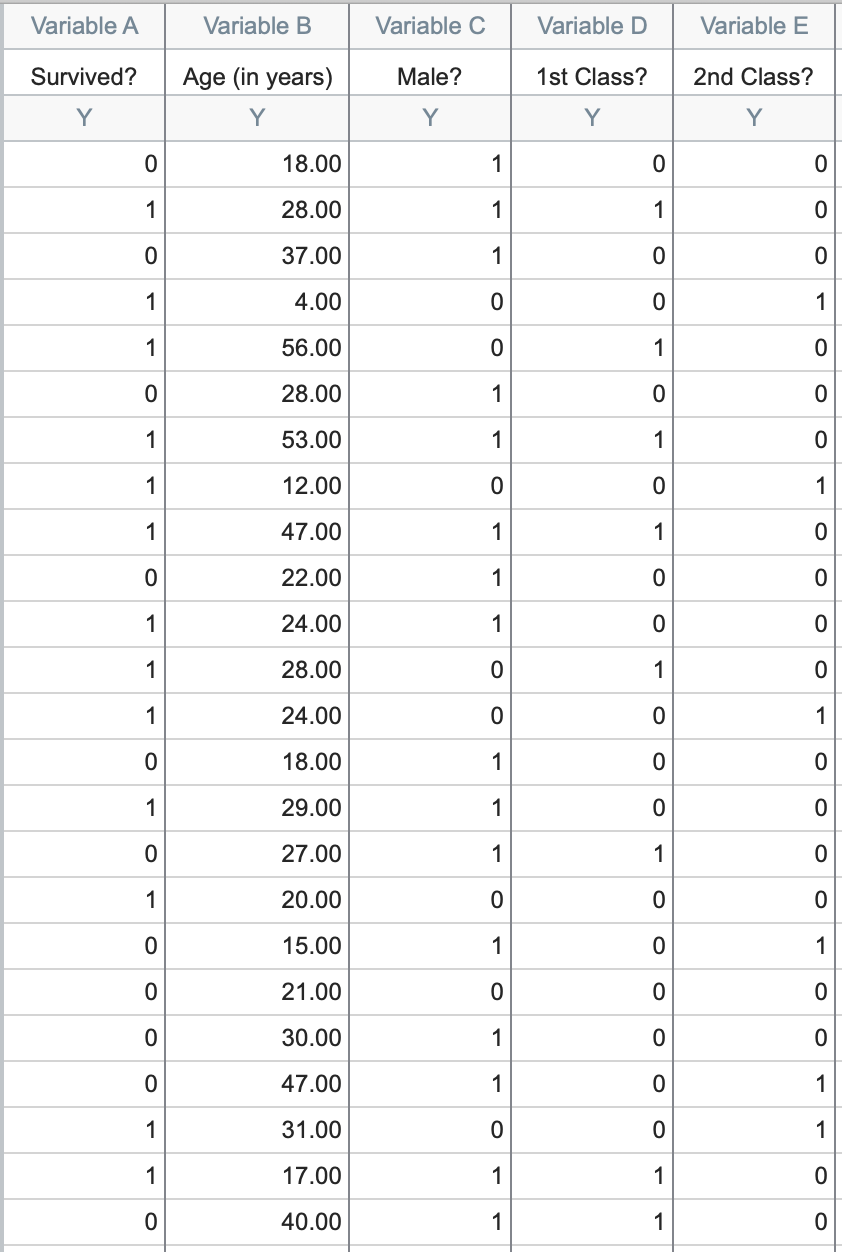
这些数据代表了“泰坦尼克号”上的 1,314 名乘客,每一行代表一名不同的乘客(请注意,该数据集未包含船员,且不同来源提供的官方乘客人数存在差异)。第一列“Survived?”记录了每位乘客的命运,1 表示该乘客生还,0 表示该乘客在船沉没时遇难。 其余四列提供了每位乘客的人口统计信息及其预订的舱位。请注意,这四列中的三列也采用了二进制编码(这些列中的所有值均为 1 或 0)。下面将简要说明这种编码方式的工作原理。若想直接进行分析,请跳至“开始分析”
那么第三类呢?(虚拟编码简要介绍)
如上所述,本数据集中的多个变量均采用1或0进行编码。在每种情况下,列标题均以问题形式呈现,若某条记录中出现1,则表示该问题的答案为“是”;若出现0,则表示该问题的答案为“否”。 例如,我们可以从上表第一行中推断出关于该乘客的一些信息。第一列中的 0 表示该乘客未幸存,年龄为 18 岁,而第三列中的 1 则表明该乘客为男性。
但这位乘客的舱等是什么?从第四列可以看出该乘客并非头等舱,从第五列可以看出该乘客并非二等舱(这两列均为0)。因此,我们可以推断这位乘客必定是三等舱(因为他既不是头等舱也不是二等舱,而这两种舱等是仅有的可能性)。
当变量属于分类型(如生/死、男/女、头等/二等/三等舱等)时,我们可以将这些响应编码为一组0和1,这一过程称为虚拟编码(虽然还有其他编码技术,但虚拟编码可能是最容易理解的)。 使用虚拟编码时,具有两个结果的变量(如幸存/死亡、男性/女性等)最终只需用一列进行编码。您不需要为“男性?”和“女性?”各设一列,因为所有信息都可以从单列中获取。 同样地,具有三种结果的变量(头等舱/二等舱/三等舱)最终会使用两列进行编码。在这种情况下,我们不需要专门为“三等舱?”设置一列,因为我们可以从另外两列的值中推断出该信息。事实上,如果您确实试图在逻辑回归模型中加入“三等舱”这一列,分析将会因变量之间的线性依赖度而失败。
启动分析
点击工具栏中的“多元逻辑回归”按钮(如下图所示),或点击工具栏中的“分析”按钮,然后从可用的多元变量分析列表中选择“多元逻辑回归”。
分析对话框
点击“多元逻辑回归”按钮后,将显示该分析的参数对话框。在本教程中,我们将直接采用大部分默认选项。下文将讨论这些默认选项的分析结果,但“多元逻辑回归”参数对话框的每个选项卡中还提供了更多可选设置。 为了便于解读结果,我们将修改“负面”和“正面”结果的标签(即输入的响应值为 0 或 1 所代表的含义)。在“负面结果”标签栏中输入“死亡”,在“正面结果”标签栏中输入“存活”。
点击“确定”后,系统将跳转至主结果表,相关内容将在下一节中进行讨论。
逻辑回归的结果
参数估计
在结果表中首先看到的是控制数据,以及 β0 的标准误差和 95% 置信区间,此外还有模型中每个成分(主效应或交互作用)的一个参数估计值。在此案例中,我们得到了截距(β0)的参数估计值以及四个主效应的估计值。
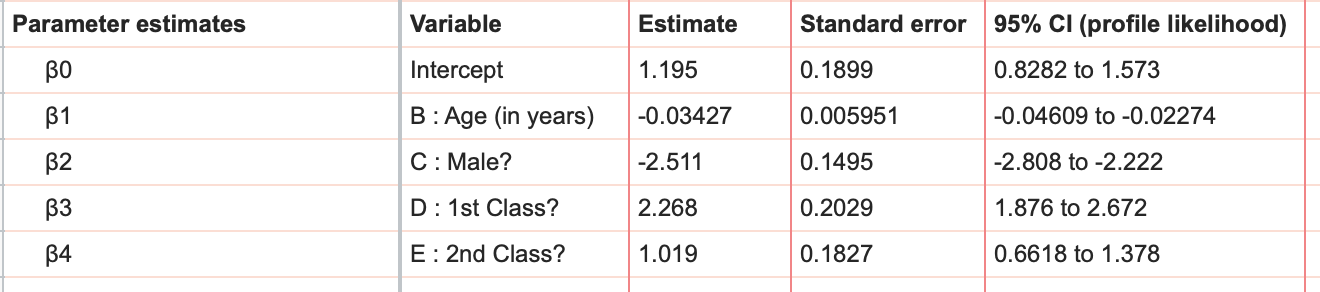
由于逻辑回归对数 odds 进行建模,因此这些参数的解读与线性回归略有不同。在尝试解读这些参数估计值之前,请确保您已掌握对数 odds、几率和概率之间的关系。在本示例中,我们可以看到“Male?”的估计值为 -2.511,而“1st class?”的估计值为 2.268。 这意味着,如果一名乘客是男性(其他所有变量保持不变),其生存的几率会减少2.511;而如果一名乘客乘坐头等舱(其他所有变量保持不变),其生存的几率会增加2.268。
优势比
除了以对数比值形式呈现结果外,Prism 还会报告优势比及其 95% 置信区间(位于结果表的下方)。
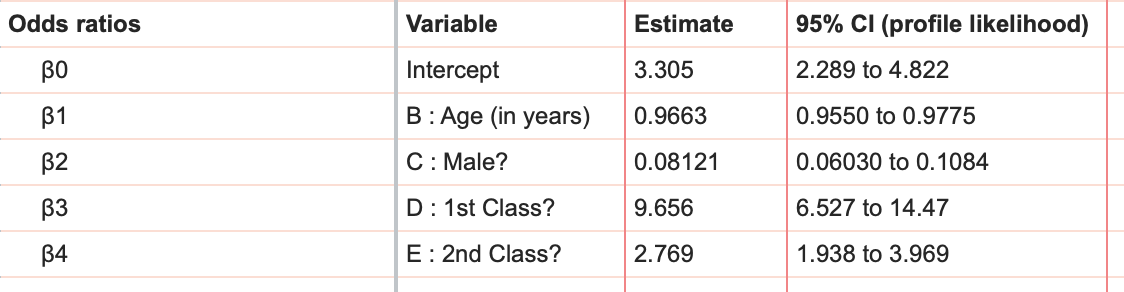
关于优势比的更详细解释可参见此处,但每个变量(β1、β2、β3 和 β4)的优势比告诉我们:该变量增加 1 单位,成功概率将乘以优势比的数值。 “年龄(以年为单位)”的优势比比报告为 0.9663。这意味着乘客年龄每增加一岁,其生存概率就会乘以 0.9663。由于该优势比小于 1,这意味着随着乘客年龄的增长,其生存概率实际上会下降(在其他所有因素保持不变的情况下)。
另需注意的是,由于我们对部分变量采用了虚拟编码,这些优势比假设了这些乘客具有某种“默认”或“参考”状态。 例如,我们可以将“男性?”、“头等舱?”和“二等舱?”这三个变量设为零,以探究年龄对生存几率的影响。然而,由于采用了虚拟编码,我们实际观察到的其实是年龄对三等舱女性乘客生存几率的影响。 假设我们测算出一名25岁三等舱女性乘客的生存几率。在此情况下,“Male?”、“1st Class?”和“2nd Class?”的取值均为0,所得的几率为1.402。 基于此,我们可以快速推算出25岁头等舱女性乘客的生存几率(几率 = 1.402 × 9.656 = 13.538)。因此,在使用虚拟编码时,优势比实际上告诉我们,相对于参考案例,几率发生了怎样的变化。
概率与优势的回顾
如果您尚未了解概率与几率之间的关系,这里有一个简要总结:
几率 = 成功概率 / 失败概率
由于失败概率即为 1 - 成功概率,我们可以将其写为:
几率 = (成功概率) / (1 - 成功概率)
例如,假设成功概率为75%,则优势计算如下:
几率 = 0.75 / (1 - 0.75) = 0.75 / 0.25 = 3
通常,我们会说“优势是3:1”(读作“三比一”)。
P 值
默认情况下,结果中不会给出参数估计值的 P 值,因此本文将不作讨论。不过,您可以通过“多元逻辑回归参数”对话框中的“选项”选项卡选择显示这些值。如果您选择让 Prism 报告这些值,还应阅读关于如何解读这些值的说明。
模型诊断
多元逻辑回归结果的下一部分提供了若干有用的模型诊断指标,用于判断数据与所选模型的拟合程度。默认情况下,此处报告的两个值包括“仅截距模型”和“所选模型”的自由度以及校正后的赤池信息准则(AICc)。这两个模型的描述相当简单:
•仅截距模型:仅包含截距项 β0 的逻辑回归模型。该模型在预测结果时不使用任何独立变量。因此,对每个案例的预测结果均相同。
•所选模型:您选择用于拟合数据的逻辑回归模型
本节的结果实际上为您提供了一种方法,用于判断您所选模型是否比仅截距模型更能有效拟合数据。换言之,即您所选模型中的变量能为观测数据提供有用的信息。 判断哪个模型更适合拟合数据的方法是使用 AICc。AICc 的计算方法稍显复杂,但在此情况下的解读相当简单:AICc 值越小,表明模型拟合效果越好。鉴于仅截距模型的 AICc 值为 1746,而所选模型的 AICc 值为 1235,我们可以确定所选模型在描述观测数据方面表现更佳。
行预测
接下来要讨论的部分其实不在“主要结果”选项卡中。在主要结果表的顶部,您会看到一个名为“行预测”的选项卡。点击该选项卡后,Prism将提供所有观测值的完整预测概率列表,其中包含每个变量的完整信息:
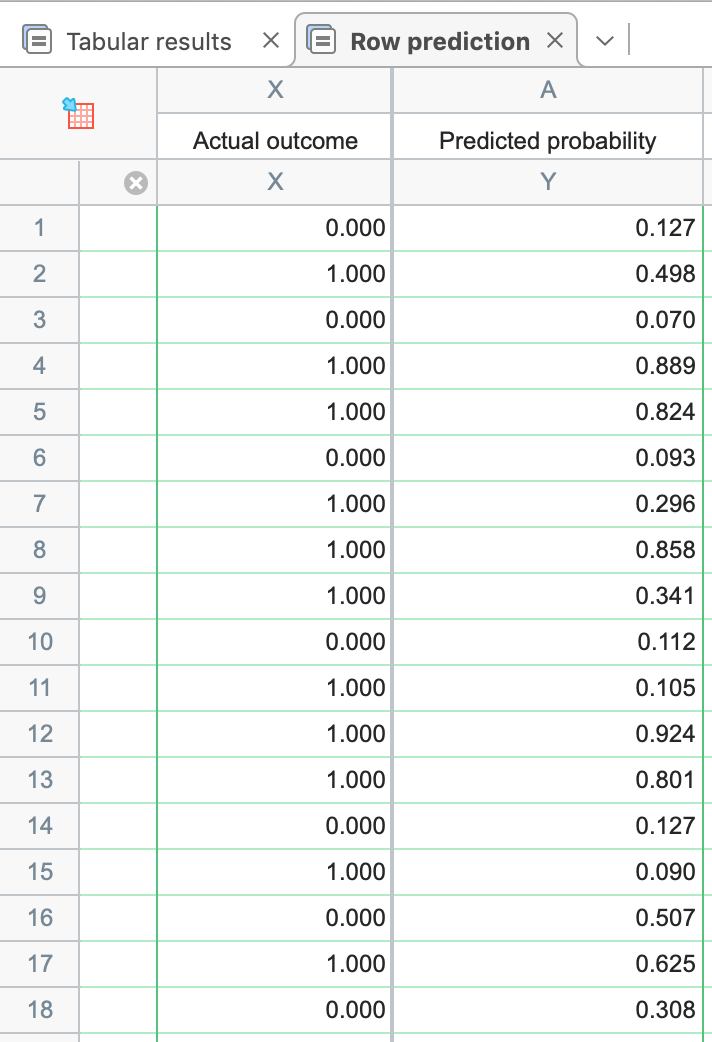
该表格提供了表中所有完整观察值的预测概率。这既包括数据中已拟合的观察值,也包括未输入Y值的观察值。在本示例中,我们可以设想一位假想的乘客:男性,34岁,持有二等舱机票。 令人惊讶的是,当前数据集中并不存在这样的乘客。不过,我们可以将这位假想乘客的对应值填入原始表格第 1315 行中的相应变量中,同时将“Survived?”(是否生还)单元格留空。由于“Survived?”单元格为空,将此行添加到表格中不会影响逻辑回归的大部分结果,但 Prism 会向您显示这位假想个体生还的预测概率。
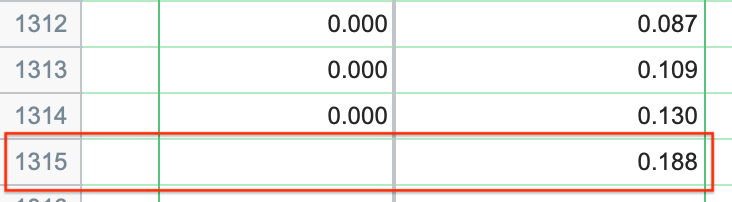
这一结果表明 - 基于其余 1314 名乘客的观测数据 - 我们这位新假设的乘客(34 岁男性,持有二等舱船票)的生存概率仅为 18.8%!
ROC曲线与ROC曲线下面积
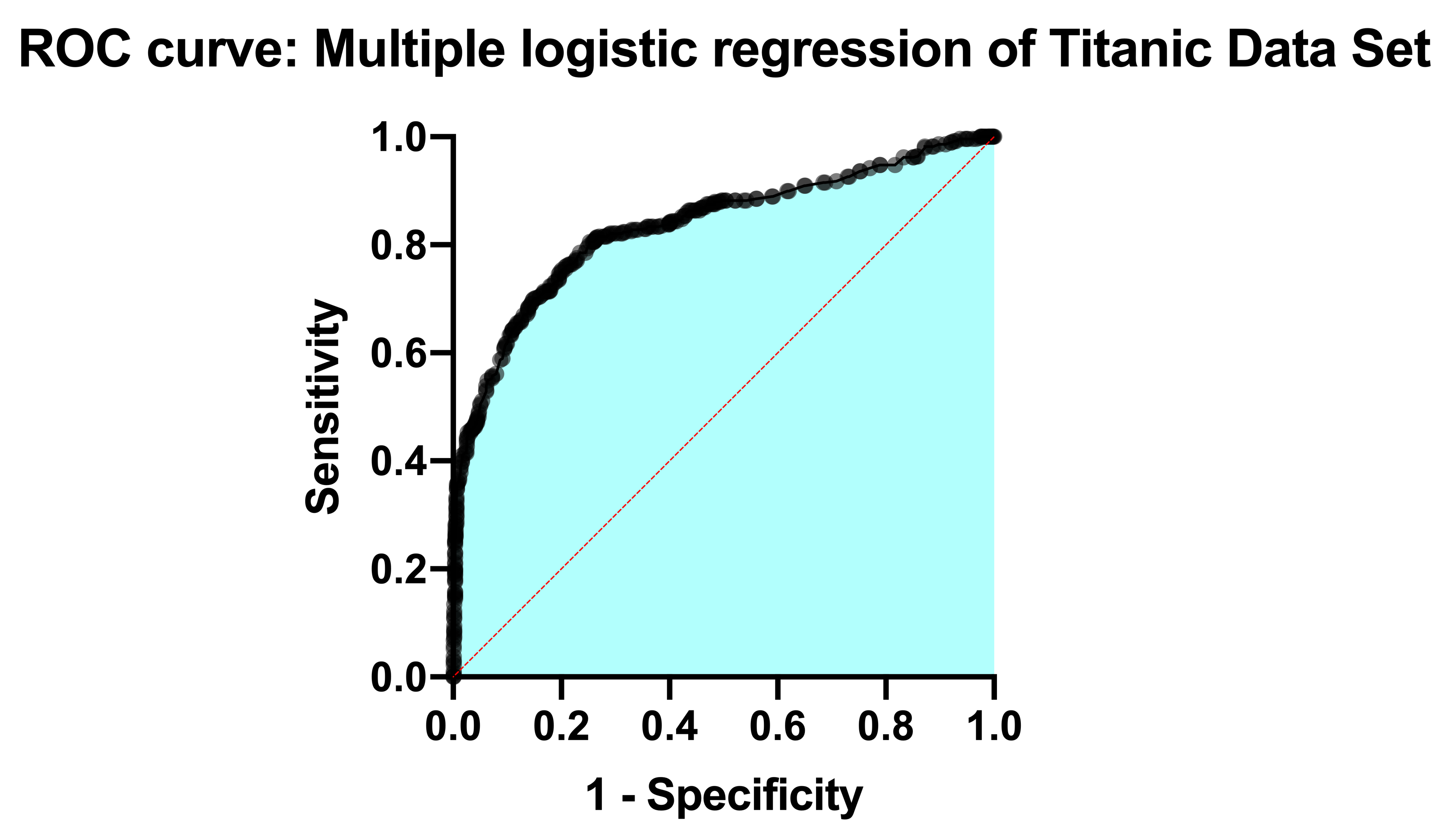
回到结果表的“表格结果”部分,接下来的部分专门讨论一种称为 ROC 曲线的内容。本次分析的 ROC 曲线在导航器的“图表”部分提供,如下所示:

理解 ROC 曲线需要一些经验,但归根结底,这些图表向您展示的是模型正确分类成功案例的能力与其正确分类失败案例的能力之间的关系。模型通过设定一个阈值来对观察值进行分类。任何预测概率大于该阈值的案例被分类为 1,而任何预测概率小于该阈值的案例则被分类为 0。 若设置极低的分类临界值,几乎可以肯定能正确分类所有观测到的成功案例。观测成功案例中被正确分类的比例称为“灵敏度”,并绘制在 ROC 曲线的 Y 轴上(Y 值为 1 表示成功案例被完美分类,Y 值为 0 表示成功案例完全被误分类)。
然而,若分类临界值设定过低,您很可能也会将许多失败案例错误地归类为成功。特异性是指正确归类为失败案例的比例,而“1-特异性”则绘制在 X 轴上(因此 X 值为 0 表示对失败案例的完美归类,X 值为 1 表示对失败案例的完全误判)。
可以想象,随着阈值的变化(从 0 到 1),被正确(或错误)分类的观察到的成功与失败之间将存在权衡。这种权衡正是 ROC 曲线所展示的:随着敏感度增加,特异性必然下降(即 1-特异性必然上升)。ROC 曲线上的每个点代表一个不同的阈值,并具有相应的灵敏度和特异性值。
ROC曲线下面积(AUC)是衡量拟合模型正确分类成功/失败情况的指标。该值始终介于0到1之间,下面积越大,表示模型的分类能力越强。 在本例中,ROC曲线(如下图所示)的AUC值为0.8889,该值与AUC的标准误差、95%置信区间及P值(零假设:AUC为0.5)一同列于结果表中。如需了解更多关于逻辑回归中ROC曲线的信息及相关数学原理,请参阅相关资料。

分类表
如前一节所述,ROC曲线下面积考虑了所有可能的阈值,用于区分观察值被预测为“成功”还是“失败”(即预测为1或0)。 在本节结果中,采用单一阈值生成了一张结果表,其中列出了观测到的 1 和 0 的数量,以及预测的 1 和 0 的数量。生成此表时使用的默认阈值为 0.5,但可在多变量逻辑回归参数对话框的“拟合优度”选项卡中手动更改。
下表展示了截断值为 0.5 时的结果:
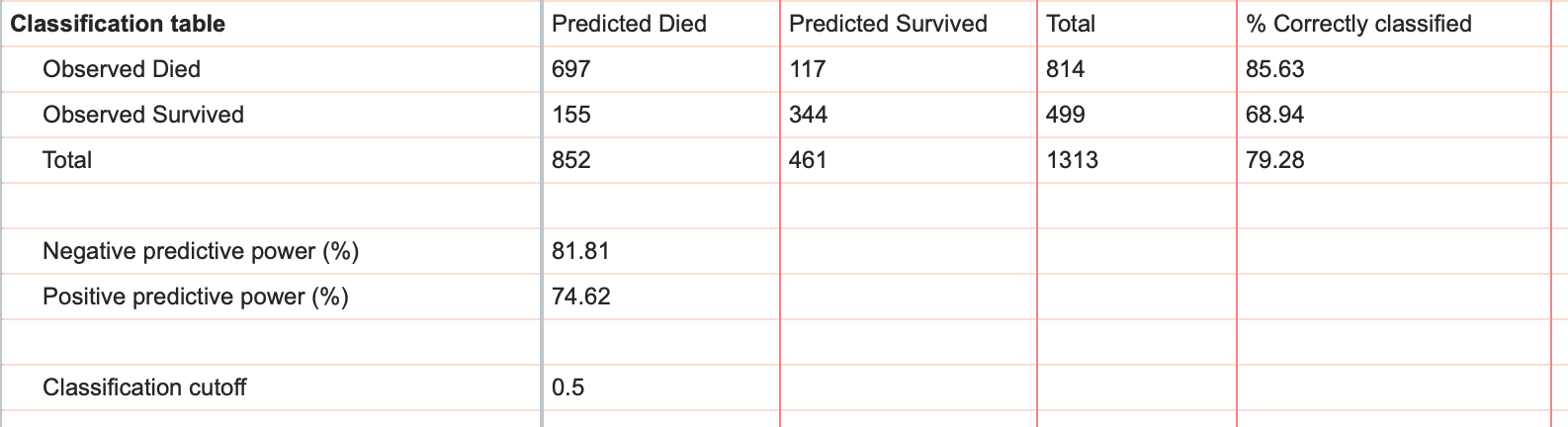
从该表格中,您可以快速查看观察到的死亡总数(814)、观察到的存活总数(499)、预测的死亡总数(852)以及预测的存活总数(461)。此外,该表格还提供了模型对每个观察到的存活和死亡案例的预测明细,以及被正确分类的观察到的存活和死亡案例所占的百分比。
最后,分类表提供了阴性预测值和阳性预测值的信息,这是评估模型性能的另一种方式。
伪R平方
量化逻辑回归模型拟合给定数据效果的另一种方法是使用称为伪R平方值的指标。 需要立即指出的是,尽管这些指标名称中含有“R²”,但它们的解读方式绝不能与线性和非线性回归中的R²相同。相反,这些值提供了关于模型拟合的不同类型信息,其取值范围在0到1之间,数值越高表明模型与数据的拟合度越好。
在 Prism 可计算的各种伪R平方值中,Tjur 的 R² 无疑是最易于解读的,也是默认报告的唯一指标。要计算 Tjur 的 R²,需分别求出观测成功案例的平均预测概率和观测失败案例的平均预测概率,然后计算这两个值之差的绝对值。这就是 Tjur 的 R²! 数值接近 1 表明观测到的 0 和 1 之间存在明显区分,而接近零的 Tjur's R² 则表明两组的平均预测概率几乎相同(即模型未能有效区分观测到的 0 和 1)。

预测值与观测值对比图
另一种直观检查所选模型在预测成功与失败方面表现如何的方法,是查看导航器“图表”部分默认提供的“预测值与观测值”图表。我们数据的图表如下所示:
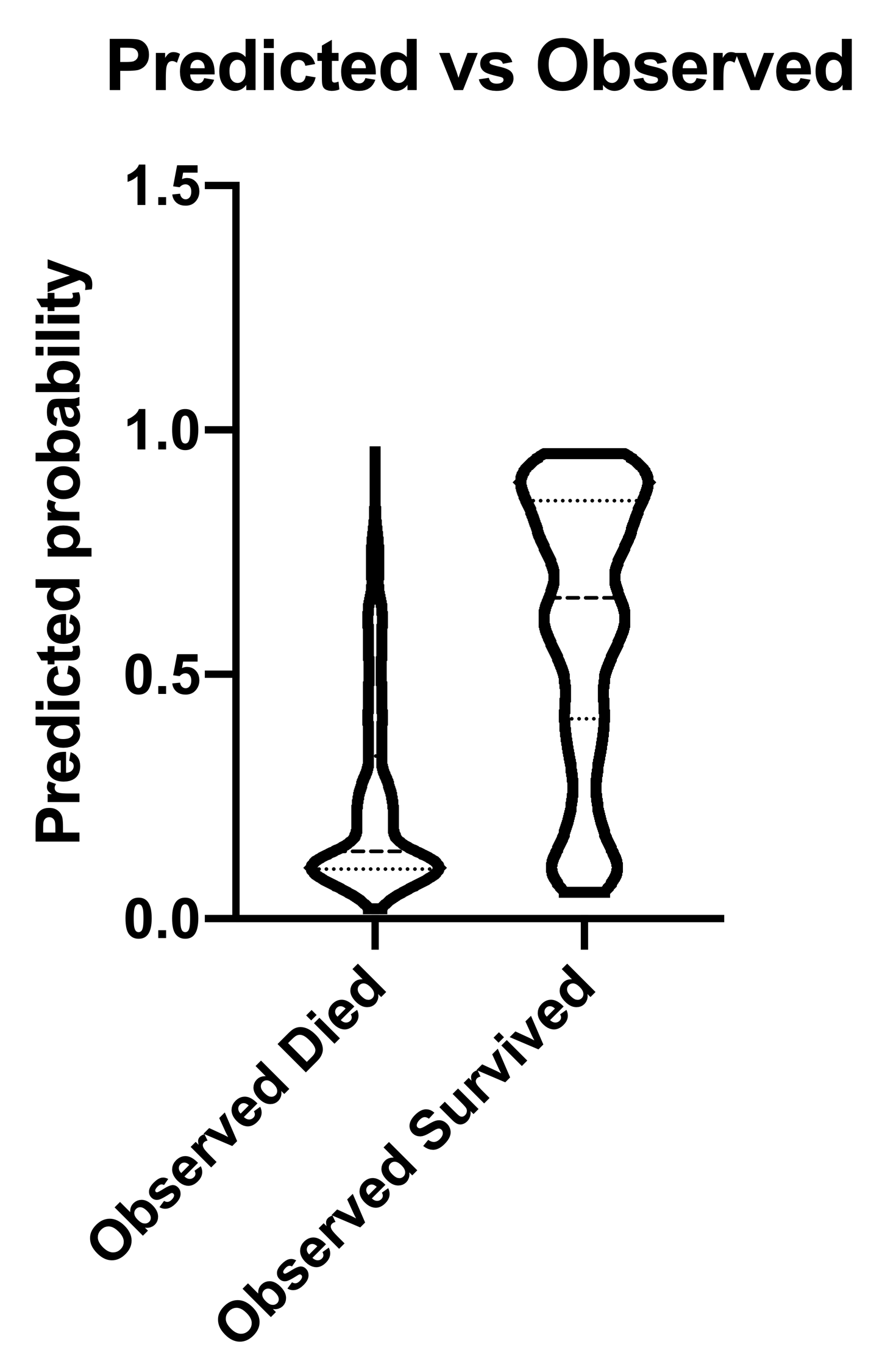
该图表的解读相当直观。从图中可以看出,存在两组人群(一组为幸存者,一组为非幸存者)。 我们还可以看到这两个群体的预测概率分布。观察死亡个体的提琴图,可见其中大多数个体的生存预测概率远低于 0.5(中位数为 0.1383,均值为 0.2411)。 此外,我们可以发现模型在分类实际幸存者群体时的表现并不理想。对于该群体,我们看到预测概率分布更为均匀(中位数为0.6564,均值为0.6068)。当然,这些预测仅基于独立变量(年龄、性别和服役类别),并未考虑实际结果。
假设检验
若返回结果表的“表格结果”选项卡,我们可以继续探究多元逻辑回归报告的其他结果。默认情况下,结果的下一部分提供了Prism用于检验模型拟合数据优劣的两种方法之一。该检验被称为Hosmer-Lemeshow检验,用于检验“所选模型是正确的”这一零假设。 该检验的具体原理稍显复杂,但根据我们的数据,我们很可能选择拒绝“指定模型是正确的”这一零假设。

鉴于这一结果,我们可能会选择进一步探究那些未包含在原始模型中、但可能影响生存概率的其他因素。然而,必须特别注意的是,研究表明霍斯默-莱梅肖检验对计算方法的细微变化非常敏感,因此Prism中包含该检验的主要目的是为了验证Prism得出的结果能否通过其他软件应用程序得到验证。
较小的P值并不一定意味着您的模型在某种程度上“不好”。毕竟,
“所有模型都是错误的,但有些是有用的……”
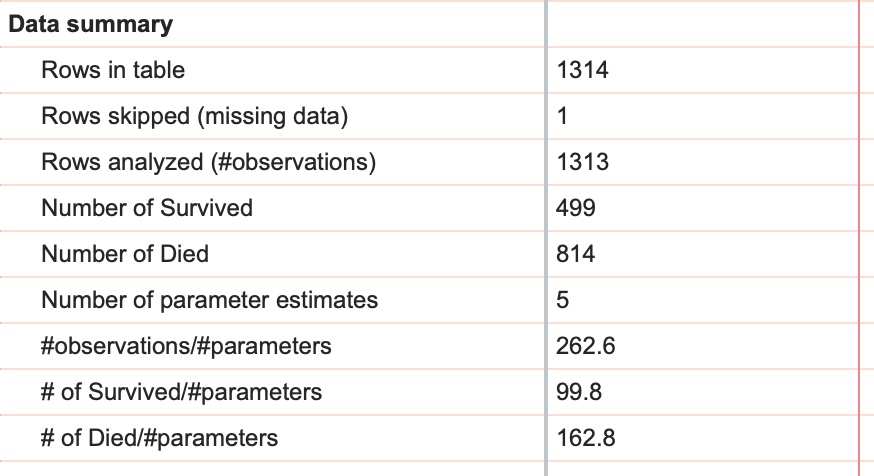
数据摘要
Prism从多元逻辑回归中提供的最终信息以数据摘要的形式呈现,其中包含数据表的行数、被跳过的行数,以及这两者之间的差值(即分析中的观测值数量)。 请注意,在我们的数据集中,表格共有 1314 行(若包含插值示例则为 1315 行),但实际分析的行数仅为 1313 行。这一差异源于一名(或多名)乘客的结局(存活或未存活)未知,因此在拟合模型时跳过了这些行。
此外,在数据摘要中,1 的总数和 0 的总数分别显示为“幸存人数”和“死亡人数”。最后,提供了三个比率:观测值数与参数数之比、幸存人数与参数数之比,以及死亡人数与参数数之比(我们建议逻辑回归中后两个比率应至少为 10)。