Prism 为多重 t 检验(及非参数检验)分析提供了多种重要选项,允许您针对数据表的每一行从众多不同的检验方法中选择一种进行分析。

实验设计选项卡
“参数:多重 t 检验(及非参数检验)”分析对话框的第一个选项卡提供了若干选项,通过回答以下三个问题,您可以指定要执行的分析类型:
1.数据是配对的还是非配对的?
2.检验是否假设数据采样自正态(高斯)分布、对数正态分布,还是不作分布假设(非参数)?
3.(针对正态和对数正态分布假设):检验是否对方差齐性(标准偏差或几何标准偏差)做任何假设?
4.根据前两个问题的回答,Prism 应执行哪种特异性检验?
实验设计:数据是配对的还是非配对的?
第一个问题涉及被比较的每个主要组内数据之间的关系。如果选择“配对”选项,则意味着每个主要列的第一子列中的数据是配对或匹配的,每个主要列的第二子列中的数据是配对或匹配的,以此类推。选择此选项的示例包括:
•对同一受试者在不同时间点进行测量(例如,治疗前后)
•对根据年龄、种族或疾病严重程度等特征招募或配对的个体进行测量。在此情况下,一名个体可能接受一种治疗,而另一名则接受另一种治疗(或作为对照)
•您多次进行实验室实验,每次都并行处理对照组和实验组。如果不同组别之间存在难以控制的实验条件微小差异,这一点可能尤为重要
•您对具有某种固有配对关系的个体(如双胞胎或亲子配对)进行变量测量
请注意,配对应由实验设计决定,绝不能基于待分析的变量。例如,若比较两组的血压测量值,可以按年龄或体重进行配对,但不能基于其记录的血压值进行配对。
分布假设
许多统计分析对被分析数据的抽样总体都存在某些假设。统计检验中常见的假设之一与数据抽样所依据的总体分布有关。Prism 提供三种选择:
1.正态(高斯) - 假设数据来自正态分布。比较各组的平均值
2.对数正态分布 - 假设数据采样自对数正态分布。比较各组的几何均值
3.非参数 - 不假设数据采样自特异性分布。而是使用非参数检验。这通常等同于比较组内数据的秩
非参数检验不基于数据采样自高斯分布(或任何其他特异性分布)的假设。这可能使其看起来更具吸引力。然而,非参数检验的检验力较弱。决定何时使用非参数检验并非易事。
为每行选择检验
基于前两节所选的选项,在分析参数对话框的“实验设计”选项卡上需要做出的最终决定是执行哪种特异性检验。每行总共可执行七种检验,其中部分检验还需考虑其他选项。本节将详细介绍每种检验及其可用的选项。
1.非配对,正态(高斯)分布。在前两节中选择此组合选项后,需针对分析中各组的标准偏差做出最终决定。
o第一个选项不对任何行或列数据的母体标准偏差做出任何假设。选择此选项后,Prism 将执行方差不齐的非配对t检验(有时称为带 Welch 校正的非配对t检验)。对于从正态分布中抽取的非配对数据,这通常应作为您的默认选择。
o下一选项是假设 - 对于每一行 - 两个组的数据均来自具有相同标准偏差的总体(换言之,第一列某一行数据的总体标准偏差与第二列同一行数据的总体标准偏差相同)。这将针对每一行执行标准的非配对t检验,并为每一行单独估计方差。
o本节的最后一种选择允许假设所有数据(所有行中的所有组)均来自具有相同标准偏差的总体。 请注意,这并不意味着您的样本标准偏差必须完全相同。相反,此处的假设是样本中的变异性是随机的,且所有行中的数据均来自具有相同标准偏差的总体。这就是方差齐性(homoscedasticity)的假设,它会增加自由度,从而提高检验力。选择此选项后,Prism 将使用单一合并方差进行非配对t检验
2.配对,正态(高斯)分布。在前两节中选择此选项组合将导致 Prism 仅提供一种检验:
o配对t检验。该检验的零假设是每对样本差值的平均值为零
3.非配对,对数正态分布。在前两节中选择此选项组合,将导致在分析中需对各组的标准偏差做出最终决定。
o第一个选项不对任何行或列数据的母体几何标准偏差做出任何假设。选择此选项后,Prism 将针对每一行执行带 Welch 校正的对数正态 t 检验。对于从对数正态分布中抽取的非配对数据,这通常应作为您的默认选择。
o下一项选择是假设 - 对于每一行 - 两组数据均采样自具有相同几何标准偏差的总体(换言之,第一列某一行数据的总体几何标准偏差与第二列同一行数据的总体几何标准偏差相同)。 请注意,该假设等同于假设对数转换后总体方差相等。这将对每一行执行标准的对数正态 t 检验。
o本节的最后一个选项允许假设所有数据(所有行上的所有组)均采样自具有相同几何标准偏差的总体。 请注意,这并不意味着样本的几何标准偏差必须完全相同。相反,此处的假设是样本中的变异性是随机的,且所有行中的数据均来自具有相同形状参数(几何标准偏差)的总体。这是方差齐性的假设,会带来更多的自由度,从而提高检验力。选择此选项后,Prism 将执行具有单一合并方差的非配对t检验
4.配对,对数正态分布。在前两节中选择此选项组合时,Prism 仅提供一种检验:
o比率t检验。该检验的零假设稍显复杂。简而言之,其零假设为每对样本比值的对数均值为零(换言之,由于 log(1) = 0,因此每对样本的比值均为 1)
5.非配对、非参数检验。选择这一组合将导致必须在以下两种检验中选择其一:
oMann-Whitney检验。该检验的零假设可能难以理解,相关内容将在本文中讨论。但需注意,该检验的运作原理是:将待比较的两组所有数据取出,并按从小到大的顺序对所有数值进行排序(无论该数值属于哪一组)。 随后,为每个数值分配一个序数,从最小值开始为1,最大值为n(其中n为总数值个数)。该检验随后比较被比较的两组的平均序数。
oKolmogorov-Smirnov检验。该检验的零假设可能难以理解,但其假设被比较的两个组是来自具有相同分布的总体。该检验利用数据的累积分布来检验是否违反了这一零假设(中位数不同、方差不同或分布不同)。有关Kolmogorov-Smirnov检验的更多信息
6.配对非参数检验。选择此选项组合仅产生一种可能的检验:
oWilcoxon配对检验。该非参数检验首先计算待分析两组中各成对值之间的差值,为这些差值的绝对值赋予秩数,然后比较第一组成对值较高的秩和与第二组成对值较高的秩和。 该检验的原理较为复杂,本指南的其他页面提供了更多关于如何解释该检验结果的信息。
“多重比较”选项卡
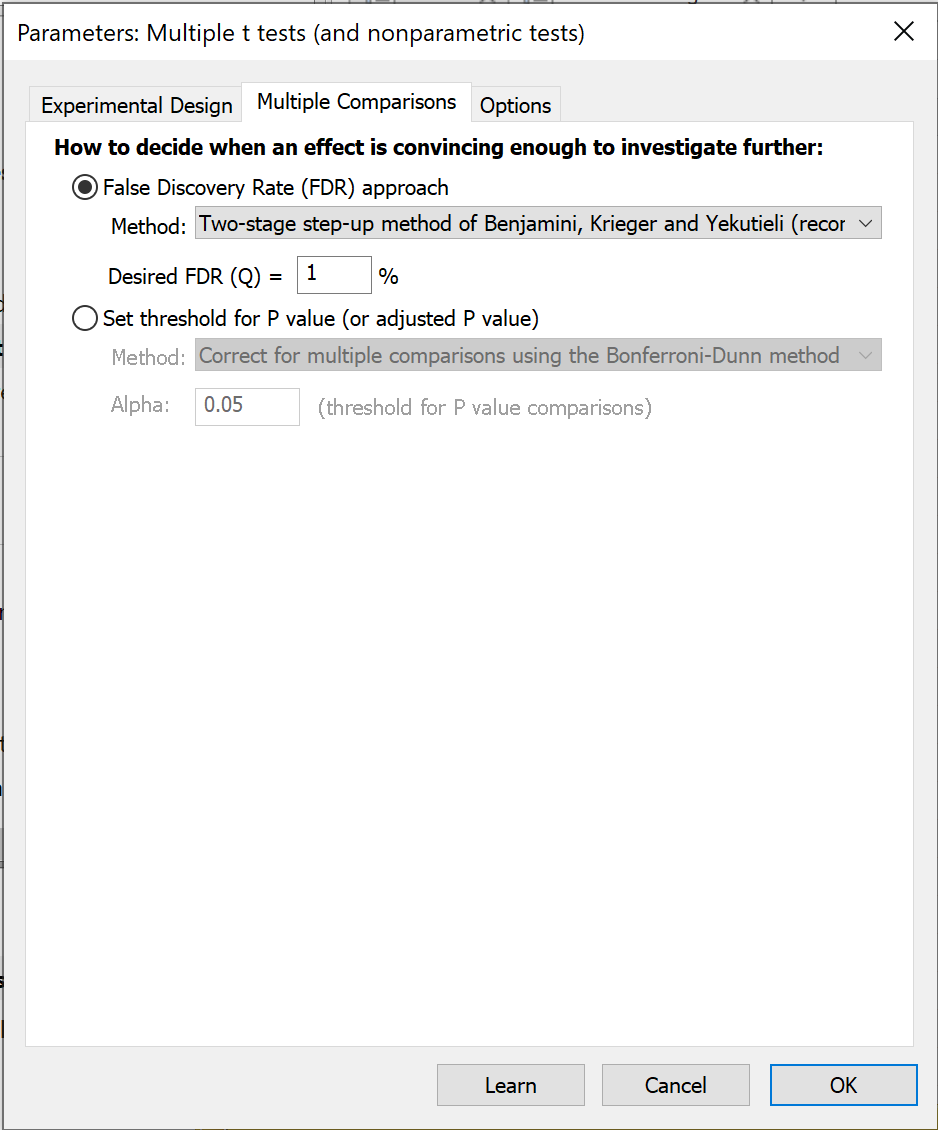
在同时执行大量 t 检验时,通常的目标是筛选出差异足够显著、值得进一步探究的比较子集。Prism 提供了两种方法,用于判断在完成多重 t 检验(及非参数)分析后,何时双尾 P 值足够小,使得该比较值得进一步研究。
一种方法基于大家熟悉的统计学显著概念。
另一种选择是基于错误发现率(FDR;推荐)进行决策。 控制 FDR 的整体思路与将某些比较判定为“统计学显著”截然不同。该方法不使用“显著”一词,而是使用“发现”一词。您需要设定 Q,即期望的“发现”中属于假发现的最大百分比。换言之,这就是期望的最大 FDR。
对于所有被标记为“发现”的数据行,目标是其中因数据随机散布导致的“假发现”比例不超过 Q%,同时至少 100% - Q% 的“发现”是总体均值之间的真实差异。了解更多关于 FDR 的信息。Prism 提供了三种控制 FDR 的方法。
如何处理多重比较
如果您选择了“错误发现率(FDR)”方法,则需要为 Q 设定一个数值,即允许被证明为错误发现的发现所占的比例。请输入百分比,而非分数。如果您愿意接受 5% 的发现为假阳性,请输入 5,而非 0.05。您还需要选择使用哪种方法。
若选择统计学显著方法,您还需就多重比较问题做出额外决策。共有四种选项:
•使用 Holm-Šídák 方法校正多重比较(推荐)。您需指定用于整个 P 值比较族(family)的阈值水平 α。该方法的设计原理是:当每个行(row)的比较所对应的零假设均为真时,所指定的 α 值代表获得一个或多个“显著” P 值的概率。
•使用 Šídák-Bonferroni 方法进行多重比较校正(不推荐)。我们建议使用 Holm-Šídák 方法(见上文),因其检验力更强。Šídák-Bonferroni 方法(通常简称为 Šídák 方法)的检验力略高于普通的 Bonferroni-Dunn 方法(通常简称为 Bonferroni 方法)。当进行大量比较时,这一点尤为明显。
•使用Bonferroni-Dunn法进行多重比较校正(不推荐)。Bonferroni-Dunn法比Holm-Šídák法更易于理解且更为人熟知,但除此之外并无其他优势。 Bonferroni-Dunn法与Šídák-Bonferroni法的主要区别在于:Šídák-Bonferroni法假设每次比较彼此独立,而Bonferroni-Dunn法则不作此独立性假设。因此,Šídák-Bonferroni法的检验力略高于Bonferroni-Dunn法
•不进行多重比较校正(不推荐)。每个 P 值均单独解读,不考虑其他比较结果。需设定显著性水平 α 的阈值,通常设为 0.05。该阈值用作比较 P 值的基准。 如果 P 值小于 α,则该比较被视为“统计学显著”。若采用此方法,请注意会产生大量假阳性结果(即许多看似“显著”的发现实际上并不成立)。在某些情况下这并无大碍,例如药物筛选,其中多次 t 检验的结果仅用于设计下一阶段的实验。
“选项”选项卡
“参数:多重 t 检验(及非参数检验)”分析对话框中的第三个也是最后一个选项卡提供了若干重要控件,用于设置分析结果的报告方式以及 Prism 将根据此分析生成何种可视化图表。
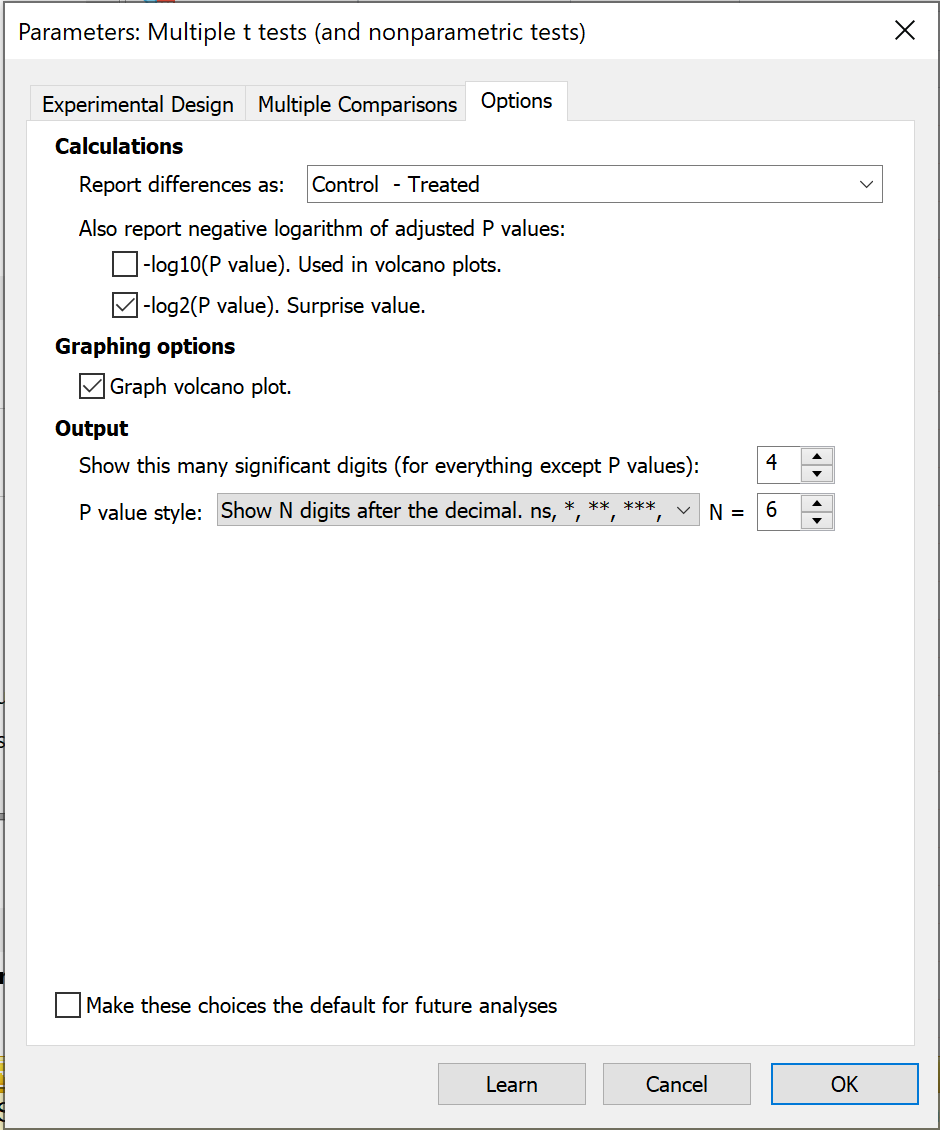
计算
在此部分,您可以选择分析中两个组别的比较顺序。例如,您可以将差异报告方式从“对照组 - 处理组”改为“处理组 - 对照组”。请注意,这不会改变检验的总体结果,仅会改变差异的“符号”。
此外,本节还提供对计算出的 P 值进行两种对数变换的选项:
•-log10(P值) - 此转换用于生成结果的火山图,该选项可用于生成这些结果的表格(便于与绘制的火山图一同呈现)
•-log2(P值) - 这是计算得出的P值的2进制对数,有时也被称为“香农信息值”、“意外值”或“S值”。对计算出的P值进行这种简单的转换,为理解P值提供了一种直观的方式。 应用此转换后得到的值 S 可按以下方式解读:我们对所获得的 P 值感到的惊讶程度,不应超过抛硬币 S 次且每次都出现正面时所感到的惊讶程度。 举例来说,假设我们得到一个 P 值为 0.125。对应的 S 值为 3,因此我们对获得 0.125 这个 P 值的惊讶程度,不应超过抛硬币三次且每次都出现正面时的惊讶程度(这并不太令人惊讶)。 现在假设我们得到的P值为0.002。对应的S值约为9,我们对得到0.002这个P值不应感到比抛硬币九次且每次都出现正面更惊讶(这要惊讶得多!)。
绘图选项
此处的复选框(默认启用)会使 Prism 为您的数据生成火山图。X 轴表示每行均值之间的差值。 Y 轴绘制 P 值的变换曲线。具体而言,它绘制的是 P 值的负对数。因此,若 P=0.01,则 log(P)=-2,而 -log(P)=2,即图中绘制的数值。因此,差异较大的行位于图表两端,而 P 值较小的行则位于图表较高处。
Prism 会自动在 X=0(无差异)处绘制一条垂直网格线,并在 Y=-log(alpha) 处绘制一条水平网格线。位于该水平网格线之上的点,其 P 值小于您选择的 alpha 值。
输出
最后,在此选项卡中提供了控制选项,允许您控制分析结果中显示的有效数字位数(P值除外),以及报告P值时采用的样式。